2020年6月,OpenAI推出了参数量达到1750亿的巨型模型——GPT-3,规模已接近人类神经元总量,毫无疑问成为了AI量变积累阶段中的一个重要进展。近期,OpenAI全新打造的ChatGPT亦是风头无俩,成为国内外AI领域的头号热门话题。
ChatGPT基于GPT-3.5架构大语言模型,是通过强化学习进行训练的人工智能聊天机器人程序,并且成功摆脱了以往对答式AI”人工智障”的马甲,能够替作家编故事,可以替商务人士出方案,甚至还能帮程序猿写程序,可谓”无所不能”。
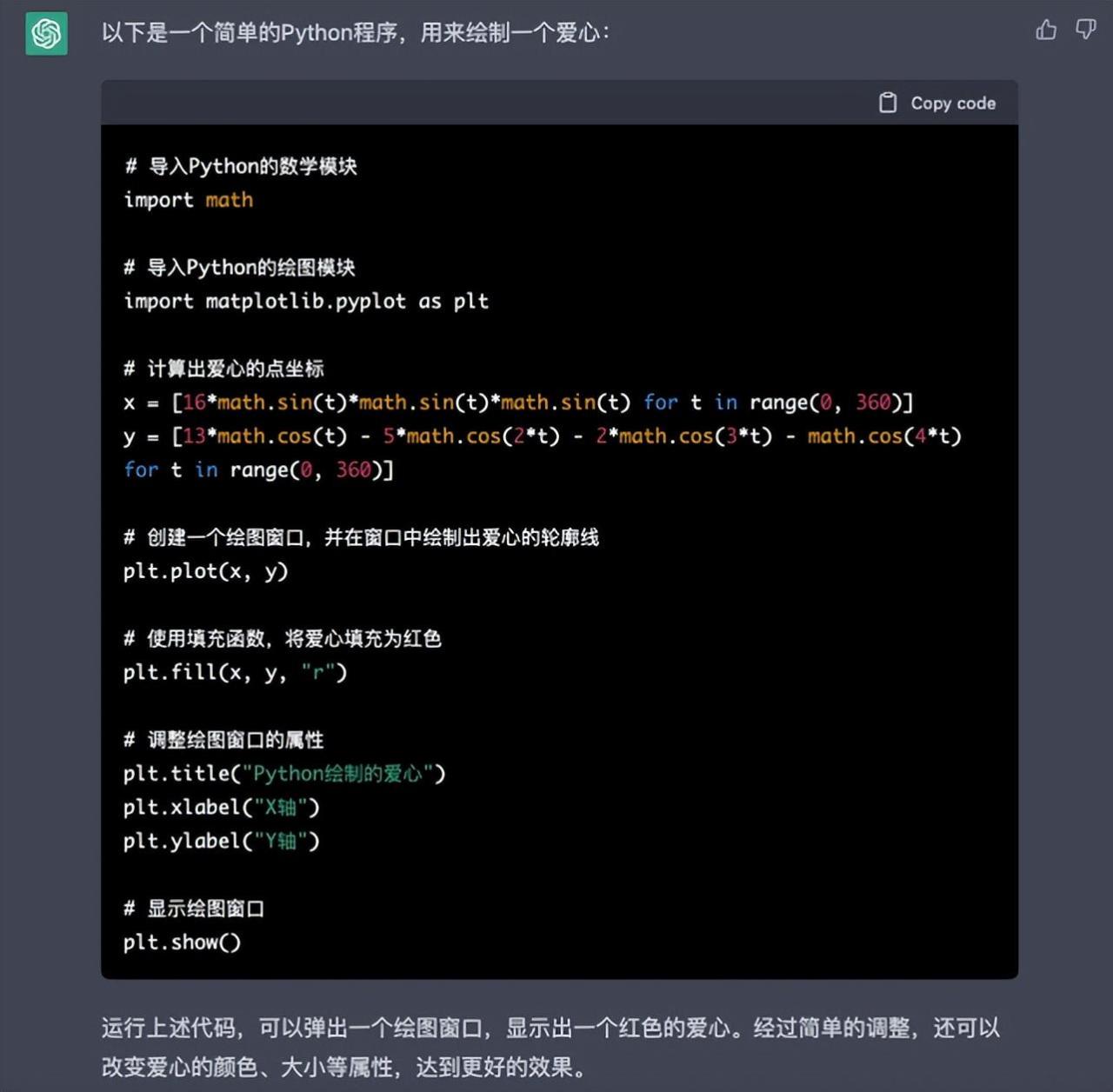
ChatGPT背后的算法基于Transformer架构,这是一种使用自注意力机制处理输入数据的深度神经网络,可以高精度的方式最大限度地收集、总结、蒸馏、修改和验证信息,广泛应用于语言翻译、文本摘要、问答等自然语言处理任务。
ChatGPT的成功离不开OpenAI对”大力出奇迹”的追捧,从GPT到ChatGPT,恰好代表了OpenAI在大模型领域走过的切实历程。从中可以看到,OpenAI凭借AI大模型已经探索出了一条属于自己的道路,成为引领AI技术前进的使者之一。
OpenAI的成功也让业界普遍的Transformer模型参数量水涨船高,参数从数百万增加至数十亿甚至数千亿,微软研究院更是成功将Transformer提升到了1000层,其所带来的性能提升也进一步推动了NLP的发展。

然而,ChatGPT虽然让我们看到了一丝强人工智能的影子和希望,但在”大力”带来真正的”质变奇迹”之前,我们须直面算力需求倍增的现实难题。更高计算密度、更大规模算力和更快训练速度的后端基础设施建设,是开创AI领域变革创新的重中之重。
超集信息作为我国高性能解决方案领域值得信赖的优秀企业,凭借43年IT整体解决方案经验传承,在计算领域不断创新突破,致力于为广大客户提供更强大、更稳定的高性能计算服务器产品及专业技术服务支持。
作为国家实验室、大型科研机构、高等院校、高新技术企业的计算解决方案优选服务商,超集信息为清华大学、北京大学、文远知行、Momenta、数坤科技、暗物智能、中国电信、国家电网、网易、微软等科研机构提供了性能优越的高性能计算解决方案,推动自动驾驶、自然语言处理、智慧医疗、智慧教育、智慧金融、移动通信等多领域的发展。

并且,面对”碳中和”、节能减排的号召,超集信息勇于创新突破,在强大研发能力和产品交付能力基础上,通过在液冷计算领域的技术创新和大量研发投入,已完成液冷高性能机架式服务器、液冷高性能静音工作站、液冷高性能边缘端工控设备等全方位液冷产品研发,并推出了稳定、高效、可靠、可执行落地的整体化液冷建设解决方案,助力客户实现高效算力升级。