ChatGPT问世以来,上海学术界和产业界已开发出MOSS、“曹植”和“魔力写作”等多个大型自然语言模型。其中,MOSS由复旦大学科研团队开发,目前在校园网内测阶段,计划本月完成升级并开源;“曹植”由达观数据公司开发,也处于内测阶段,计划今年上半年正式发布;“魔力写作Magic Writer”由竹间智能公司开发,多家企业用户正在试用,其面向个人用户的版本“灵感闪写”和“文胆”微信小程序已上线一个月。
如何看待ChatGPT引发的科研范式变革和产业变革?政府、高校院所和企业可以有何作为?三个大语言模型开发负责人谈了他们的看法。
科研范式变革涉及众多学科
“科研范式变革可以分为两个层面,一个是在众多学科领域引入人工智能,开展AI for Science(人工智能驱动的科学研究);另一个是在人工智能领域内,从传统的自然语言处理转向以大语言模型为基座的通用人工智能(AGI)研究。”复旦大学计算机科学技术学院教授、MOSS开发团队负责人邱锡鹏说。
在诸多学科领域,AI for Science近年来正在兴起。越来越多的科研人员在用人工智能系统分析海量数据,从中得出一些人脑很难想到的科学结论。2020年,“阿尔法折叠2”系统精准预测了蛋白质三维结构,被《科学》杂志评为2020年十大科学突破之一。去年,ChatGPT的惊艳亮相指出了一条新的AI for Science路径——让大语言模型“阅读”大量科学文献后,利用其生成内容的不确定性来进行“头脑风暴”,设计新的科研规划或技术路线。
在人工智能领域,ChatGPT淘汰了句法分析等一些过去很重要的研究方向,相关论文越来越少,因为ChatGPT强大的自然语言理解和生成能力表明,对大语言模型来说,句法分析等中间环节不是必需的。因此,高校院所和企业的科研团队都在转向,或自主研发大语言模型,或将自研小模型与开源大模型融合,打造混合式模型。
“灵感闪写”微信小程序
“灵感闪写”和“魔力写作”就是混合式模型产品。竹间智能创始人兼首席执行官、微软(亚洲)互联网工程院前副院长简仁贤介绍,公司将自研NLP(自然语言处理)小模型与大语言模型融合后,悉心“调教”,取得了不错的用户体验。记者打开“灵感闪写”小程序,发现它可以根据输入的词句,一键生成商业计划书、公众号文章、带货笔记等各类文本和插图。“魔力写作”除了能生成文本,还有对话能力,可以在学习企业的知识库后,回答企业员工及其客户的提问。
国内科技界要重视AGI研究
在科研范式和产业变革时期,邱锡鹏认为,国内科技界要重视通用人工智能研究,而不能只盯着GPT模型本身和这类产品的落地应用。“通用人工智能就是人工智能像人一样,可以干很多事,不再局限于某些特定任务。”他解释,“微软最近发表的测评论文说,GPT-4能力的广度和深度显示,它可以被视为AGI系统的雏形。OpenAI、谷歌、华盛顿大学等头部机构都已转向,研究以大模型为基座的AGI。”
为了在这场科技革命中不被落下,我国也要加强通用人工智能研究,包括将视觉、语音等多模态感知能力接入大语言模型,增强大模型与现实世界的交互能力,并构建以通用人工智能为核心的产学研合作生态。

邱锡鹏教授(左一)带领团队研发MOSS。(来源:复旦大学)
遵循这一思路,复旦科研团队正在升级MOSS。作为国内第一个对话式大语言模型,MOSS今年2月启动内测后引发广泛关注。目前,邱锡鹏和博士生孙天祥等人一方面在提升它的中文水平,中文词语训练量已由内测启动时的300亿增至1000亿;另一方面,他们在为MOSS添加联网搜索、图片生成等功能,让它可以上网获取新的知识,向通用人工智能系统演进。
复旦团队计划本月完成升级并开源,公布MOSS模型参数和训练细节,与学术界和产业界分享大语言模型开发经验,还能让企业在开源模型基础上开发各种应用,促进产业生态繁荣。
建议发挥新型举国体制优势
谈及大语言模型产业前景,达观数据董事长兼首席执行官陈运文预测,产业上游是算力供应商,中游是百度等开发C端通用大模型的大企业和开发B端服务大模型的企业,下游是开发各种应用的中小企业。其中,B端服务大模型的参数量是C端通用大模型的1/5~1/3,适合较大规模的企业开发。
达观数据研发的“曹植”就是一个B端服务大模型,参数量超过500亿,公司希望它像曹植那样有“七步成诗”能力,成为满足金融、政务、制造等行业需求的智慧大脑。它拥有ChatGPT的所有功能,可以生成贷后管理报告、投行申报文档、法律文书等各类文本,也可以与用户对话。“我们想打造垂直、专用、自主可控的国产大模型。”陈运文说,“为了能生成长篇专业文本,比如上百页的报告,我们开发了一个能输入复杂指令的表单界面,有望为企业员工大幅减负。”
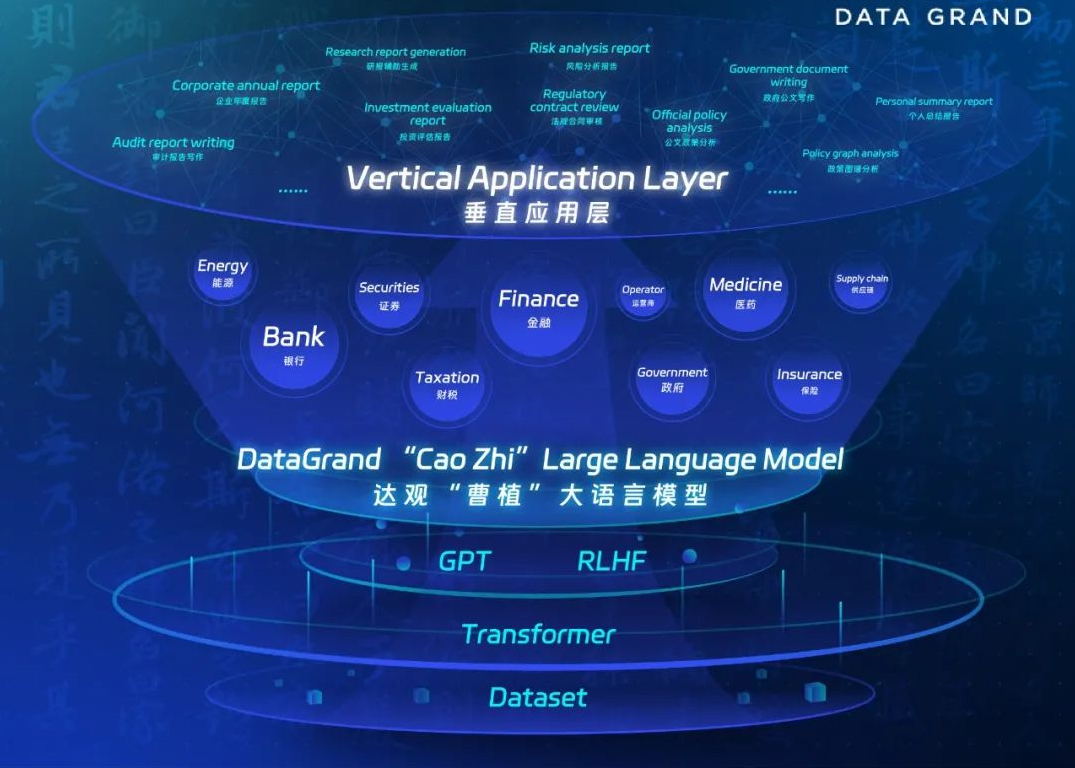
“曹植”大语言模型架构(来源:达观数据)
在研发过程中,达观数据也有些烦恼——公司只有100张GPU(图形处理器)卡,而要“跑”大模型,至少需要1000张GPU卡。为此,陈运文只能到处“化缘”借卡。在他看来,新型举国体制适用于大语言模型研发和产业化,国家和地方政府可建立人工智能公共算力池,租给企业和高校院所使用。“一张A800 GPU卡的价格是8万元,公共算力池可配备5000—10000张卡,所以建设成本在10亿元内。开发大模型产品的企业可分时租用池里部分GPU,大幅节省自购算力资源的成本。”
新型举国体制还可在大模型的中文预训练中发挥作用,推动图书馆、出版社、新闻机构等拥有高质量中文语料库的单位与人工智能企业合作,提高大模型的中文知识水平。
简仁贤也表达了人工智能企业的心声:在这轮产业变革中,希望政府和投资机构更多地关注、支持中小企业。大模型并非只有“BAT”等巨头才“玩得起”,事实上,OpenAI就属于创业期的中小企业。创业公司决策效率高、创新能力强的优势,在大模型技术创新中得到了充分体现。“就像OpenAI与微软的合作一样,创业公司与大企业、投资机构联手,有望开发出颠覆性产品。”