如今,大语言模型已经彻底改变了自然语言处理 (NLP)的研发现状。众所周知,增加语言模型的规模能够为一系列下游 NLP 任务带来更好的任务效果,当模型规模足够大的时候,大语言模型会出现涌现现象,就是说突然具备了小模型不具备的很多能力。
本文整理自 3 月 11 日 「ChatGPT 及大规模专题研讨会」上,来自新浪微博新技术研发负责人张俊林《大型语言模型的涌现能力:现象与解释》的分享,介绍了大语言模型中的涌现现象,以及关于涌现能力背后原因的相关猜想。
张俊林,中国中文信息学会理事,新浪微博新技术研发负责人
此次分享的内容主要分为五大板块,分别是:
一、什么是大模型的涌现能力
二、LLM 表现出的涌现现象
三、LLM 模型规模和涌现能力的关系
四、模型训练中的顿悟现象
五、LLM 涌现能力的可能原因
备注:想观看本次研讨会的小伙伴可以移步「CSDN视频号」查看直播回放,也可以点击「阅读原文」查看。
什么是大模型的涌现能力
复杂系统中的涌现现象
复杂系统学科里已经对涌现现象做过很久的相关研究。那么,什么是“涌现现象”?当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为“涌现现象”。

生活中的涌现现象
在日常生活中也有一些涌现现象,比如雪花的形成、堵车、动物迁徙、涡流形成等。这里以雪花为例来解释:雪花的构成是水分子,水分子很小,但是大量的水分子如果在外界温度条件变化的前提下相互作用,在宏观层面就会形成一个很规律、很对称、很美丽的雪花。
那么问题是:超级大模型会不会出现涌现现象?显然我们很多人都知道答案,答案是会的。
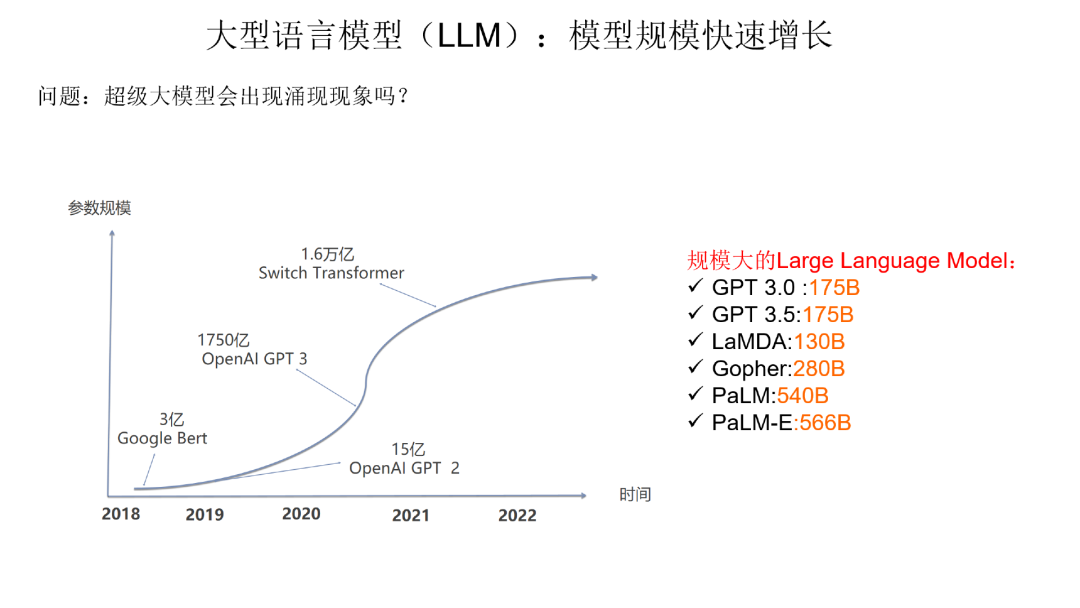
大语言模型参数增长示意图
我们先来看下大语言模型的规模增长情况。如果归纳下大语言模型在近两年里最大的技术进展,很有可能就是模型规模的快速增长。如今,大规模模型一般超过 100B,即千亿参数。如 Google 发布的多模态具身视觉语言模型 PaLM-E,由540B 的 PaLM 文本模型和 22B 的 VIT 图像模型构成,两者集成处理多模态信息,所以它的总模型规模是 566B。
大语言模型规模不断增长时,对下游任务有什么影响?
对于不同类型的任务,有三种不同的表现:
第一类任务表现出伸缩法则:这类任务一般是知识密集型任务。随着模型规模的不断增长,任务效果也持续增长,说明这类任务对大模型中知识蕴涵的数量要求较高。
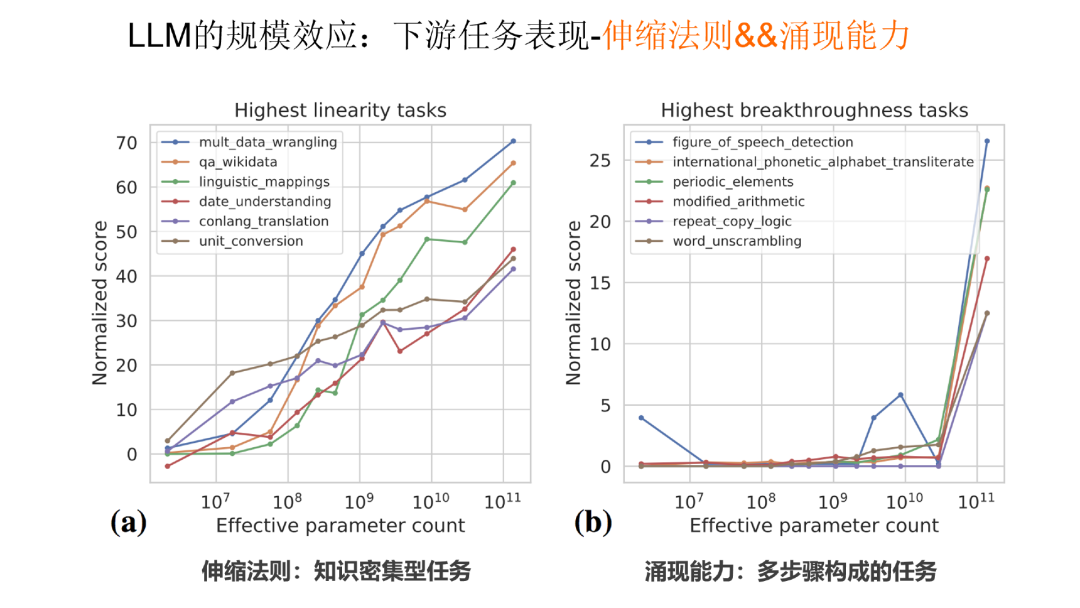
伸缩法则与涌现能力
第二类任务表现出涌现能力:这类任务一般是由多步骤构成的复杂任务。只有当模型规模大到一定程度时,效果才会急剧增长,在模型规模小于某个临界值之前,模型基本不具备任务解决能力。这就是典型的涌现能力的体现。这类任务呈现出一种共性:大多数是由多步骤构成的复杂任务。
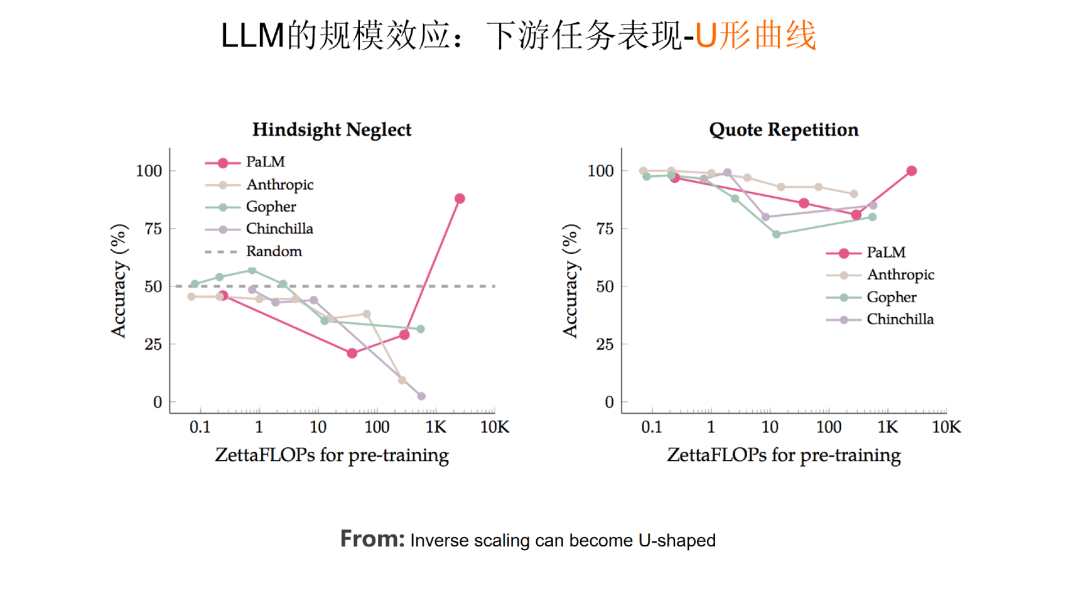
第三类任务数量较少,随着模型规模增长,任务效果体现出一个 U 形曲线。如上图所示,随着模型规模增长,刚开始模型效果会呈下降趋势,但当模型规模足够大时,效果反而会提升。如果对这类任务使用思维链 CoT 技术,这些任务的表现就会转化成伸缩法则,效果也会随着模型规模增长而持续上升。因此,模型规模增长是必然趋势,当推进大模型规模不断增长的时候,涌现能力的出现会让任务的效果更加出色。
LLM 表现出的涌现现象

目前有两大类被认为具有涌现能力的任务,第一类是 In Context Learning(“Few-Shot Prompt”),用户给出几个例子,大模型不需要调整模型参数,就能够处理好任务(参考上图给出的情感计算的例子)。
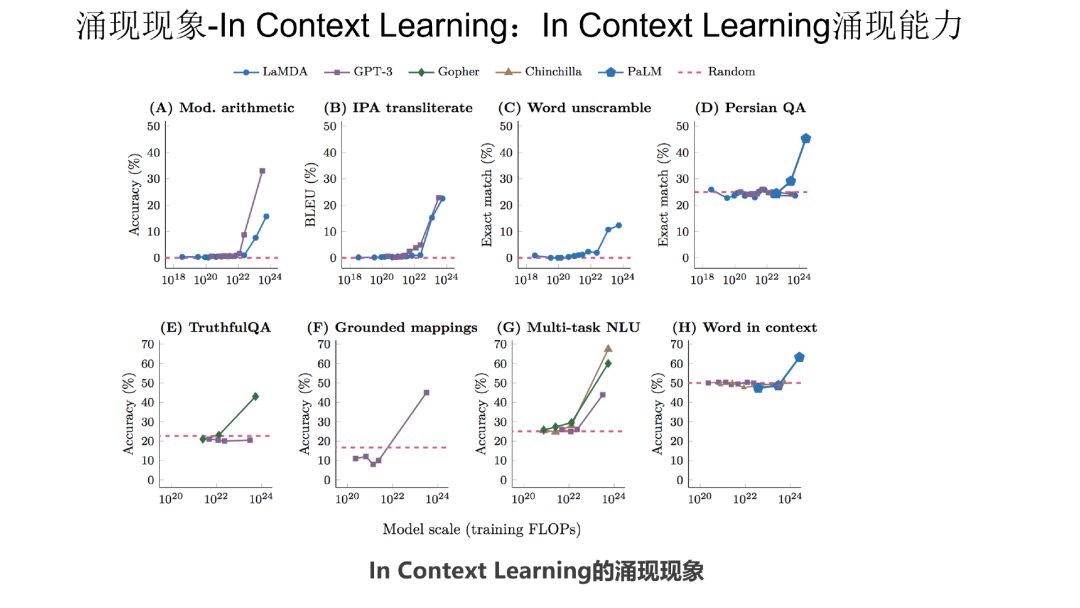
如上图展示,利用 In Context Learning,已经发现在各种类型的下游任务中,大语言模型都出现了涌现现象,体现在在模型规模不够大的时候,各种任务都处理不好,但是当跨过某个模型大小临界值的时候,大模型就突然能比较好地处理这些任务。
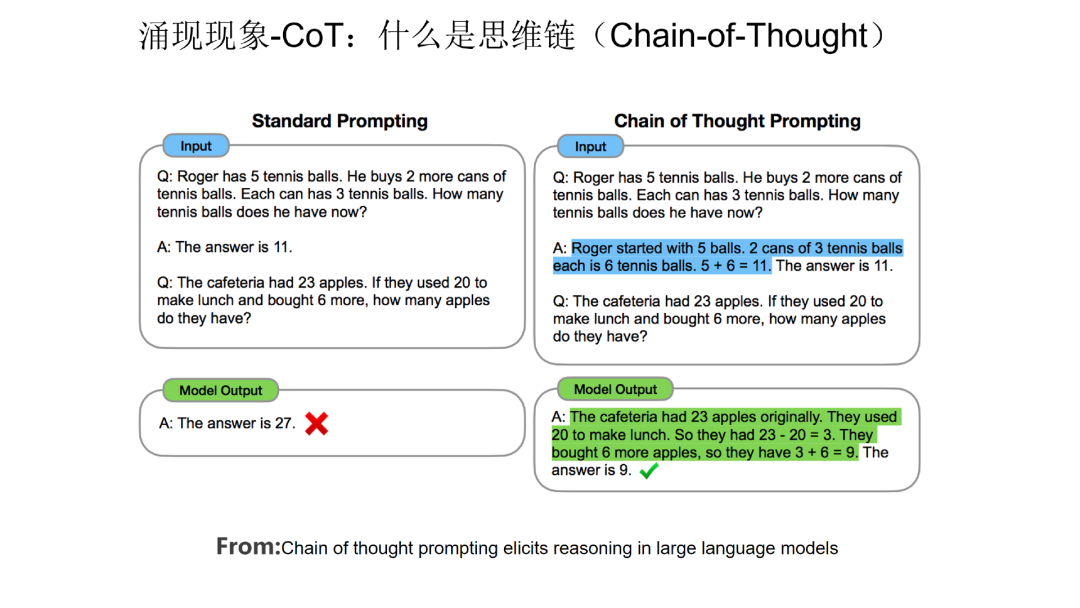
第二类具备涌现现象的技术是思维链 (CoT)。CoT 本质上是一种特殊的 few shot prompt,就是说对于某个复杂的比如推理问题,用户把一步一步的推导过程写出来,并提供给大语言模型(如下图蓝色文字内容所示),这样大语言模型就能做一些相对复杂的推理任务。
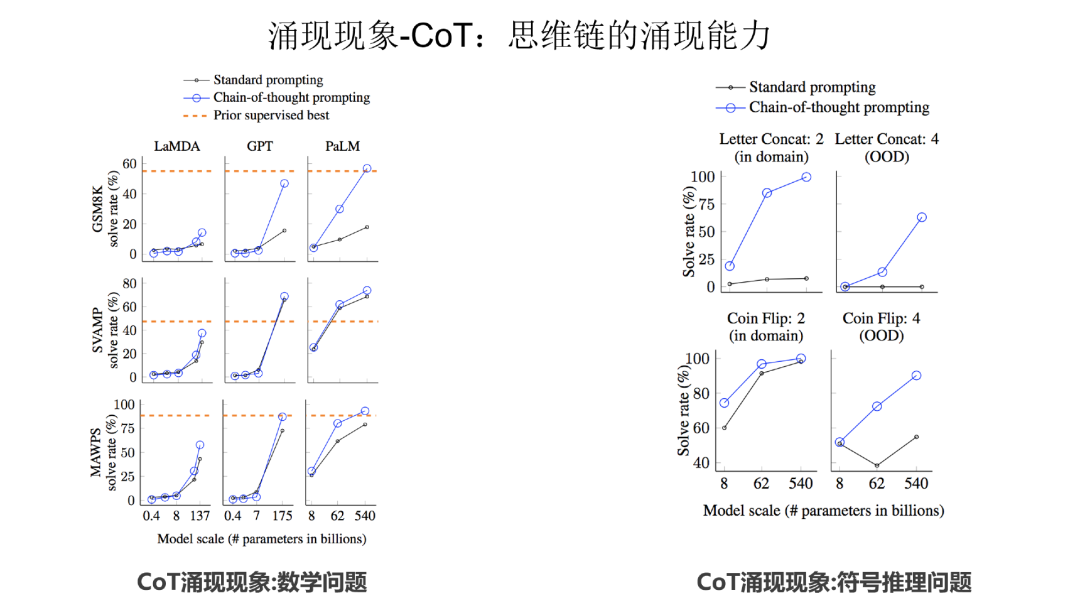
从上图可以看出,无论是数学问题、符号推理问题,CoT 都具备涌现能力。