如果技术发展的历史有大小年之分,2022年应该算是人工智能(Artificial Intelligence,AI)历史上的一个“中”型年份——它比不上2012年,那一年,工程师们第一次叠出了5层人工神经网络,“深度学习”的概念就此诞生;也比不上2016年,那一年,人类最优秀的围棋选手李世石被一个叫AlphaGo的AI打败。
但2022年的人工智能领域绝对比2016年之后任何一年结下的硕果都多。
4月,一个叫DALL-E 2的模型几秒钟就能根据指令生成令人眼前一亮的图像画作;11月末,一个叫ChatGPT的模型又横空出世,富有逻辑地接住了来自人类的任意发问——除了天气预报。两个模型都由一家位于旧金山的人工智能公司OpenAI开发。
ChatGPT官网对其的介绍是优化对话的语言模型。
一个月后,总部位于伦敦的Deepmind也发布了一个可以写代码的模型AlphaCode。从名字就能看出,它是该公司旗下围棋高手AlphaGo和蛋白质预测大师AlphaFold的兄弟。
此前,AI普遍擅长分析,比如判断一个邮件是否为垃圾邮件、辨别一张图片是苹果还是梨或者猜测你喜欢哪一类型的商品。与这类“分析式人工智能”(Analytical AI)不同,2022年诞生的DALL-E 2、ChatGPT和AlphaCode都是“生成式人工智能”(Generative AI),相较于分析,它们更擅长创造。

DALL-E 2的代表作。根据官网介绍,DALL·E 2 可以根据文字描述创建原创、逼真的图像和艺术作品。
可以肯定的一点是,无论分析式AI还是生成式AI,都仍然基于深度学习。过去两周,体验过ChatGPT的人多数都会经历这么一个过程:初试惊艳,为ChatGPT可以给出如此富有逻辑的答案而惊叹,它写出的述职报告差不多改一改就能用;有人用它为代码debug,还有人用它编出了情节离奇富有创意的科幻故事;但很快,大家又发现,这个AI在很多问题上的回答并不靠谱,比如,它会认为贾宝玉应该娶贾母,或者一本正经地给出“4是无理数”的证明。
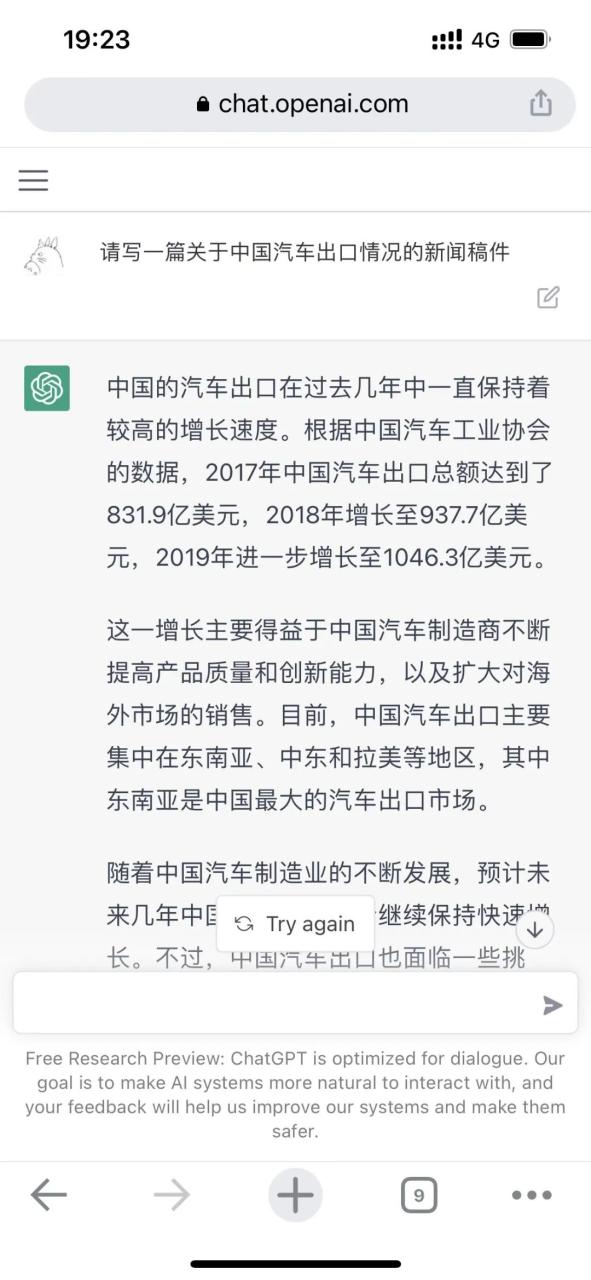
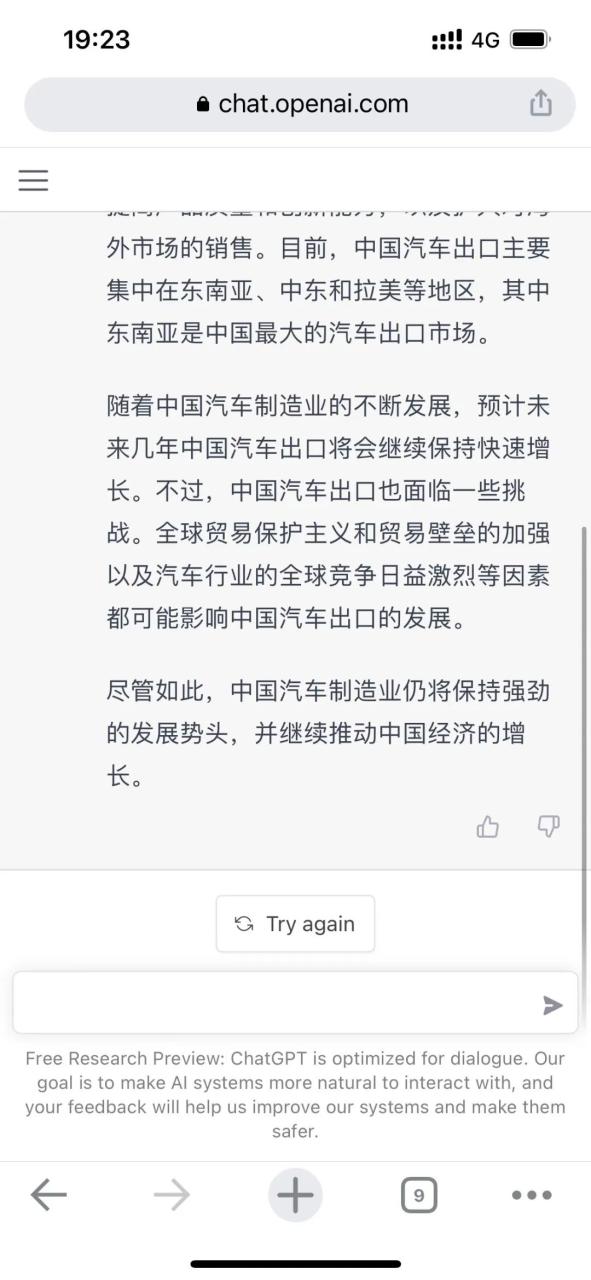
我们的一位同事给ChatGPT出了一道题,这是它给出的答案。
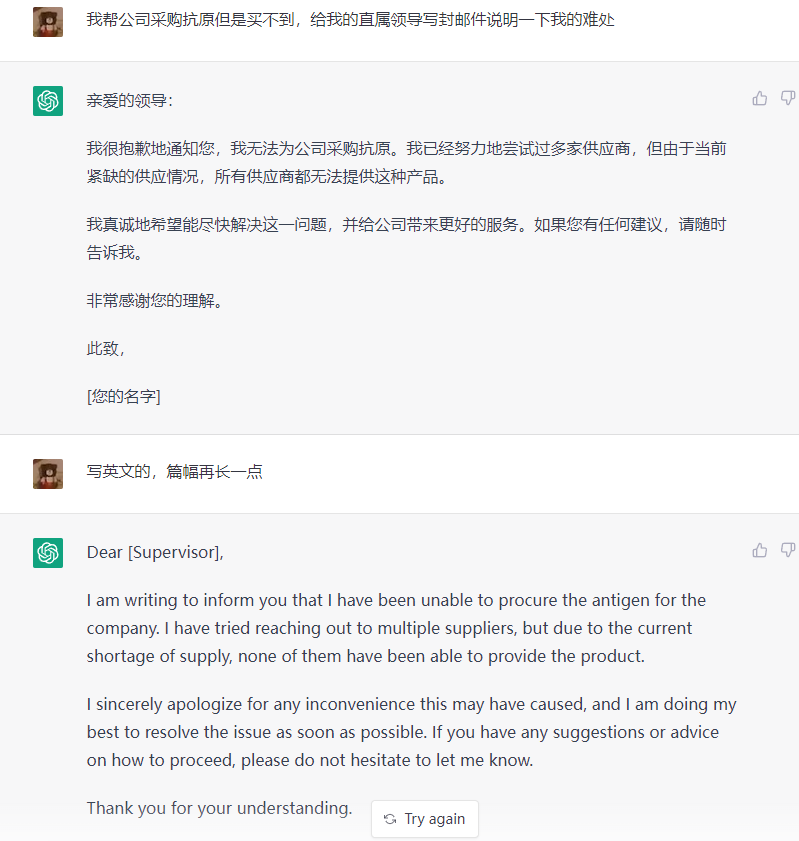
还有人让ChatGPT“给领导写信”。

但如果你问ChatGPT如何看待林黛玉倒拔垂杨柳……
没错,ChatGPT的背后仍然是深度学习的“黑盒”,你不知道它会生成什么内容,它自己也不知道。
但现在,用以深度学习的神经网络规模变了。在ChatGPT被推出之前,OpenAI就因一系列GPT(Generative Pre-trained Transformer,生成式预训练语言模型)而闻名,其中GPT-3一度是全球最大的自然语言模型,有1750亿个参数。GPT证明,更大的模型的确效果更好——至少比之前面世的所有聊天机器人都更连贯、更富有逻辑和创意。但这仍远不是最终答案。
语言一直被视为智力的明珠,无论对人还是对人工智能都如此。GPT系列一诞生就被寄予厚望,这部分人认为人类语言没什么神秘的,就是一种“Predict The Next Word”模式。回想一下,你是不是经常在听到对方讲出上一个词的时候就能预测到他接下来要说的词是什么?没错,GPT的拥趸认为一切基于概率,语言也一样,而概率基于统计,前面讲过的话几乎可以决定接下来会说出的话。
但也有持谨慎态度的人,他们认为,人类的语言没有那么简单,因为语言反映的不只是词与词之间的关系,更包括词与外部世界之间的关系,所以只玩文字游戏不能从根本上解决问题。
那么,一个仍然只是在玩文字游戏的AI还值得我们对它认真吗?或者,我们该如何看待它的价值?若要实现更好的智能,前沿的算法开发者们在做什么?
第一财经Yimagazine与资深算法工程师徐昳昶就ChatGPT的相关技术问题做了一次对谈。徐昳昶是社交应用即刻的算法负责人 ,他毕业于复旦大学计算机系,2018年加入即刻,长期关注推荐搜索的技术趋势,同时对NLP(神经语言程序学)、音频等方向也多有涉猎。
Yi = YiMagazine
徐昳昶 = 即刻算法工程师
一次只能预测一个单词
Yi:你用ChatGPT的体验如何,觉得它很好?很蠢?还是相比其他AI有进步?
徐昳昶:其实是有一些进步了,但是这个进步和之前的DALL-E 2模型(注:OpenAI旗下的图片生成模型)一样,只是向前跨出了让大家觉得好玩的一步,所以才流传这么广。这一步背后的技术变化可能不是很大,比如可能只是准确率从85%提升到了90%,只是5个点的进步,但这一步让它正式迈入应用级行列了。
Yi:准确率是基于什么?
徐昳昶:这只是一个通俗说法,比如一个分类模型,给它100张图片,它分对了80张,那么它的准确率就是80%,分对了90张,准确率就是90%。不同模型实际上有不同的评判标准,像这种生成式模型,其实更多是看用户体验。训练的时候,会有人来告诉它生成的内容到底好还是不好。比如ChatGPT,它在网页上也会有点赞或倒赞的反馈按钮让你去选。令人满意的答案就会多出,不满意的答案就会少出,以此迭代模型。
Yi:这种生成式AI如何从零开始生成一个答案?
徐昳昶:它基于的是自然语言模型,这种语言模型2000年左右就出现了,本质就是“predict the next word”,预测下一个词。比如我跟你说:“He is a ……”,让你预测下一个词是什么。如果用两个模型来做这件事,其中一个模型给出的词是“yes”,另一个模型给出的词是“man”,你觉得哪个词更可能出现?还有的模型可能会给出“king”。对有的用户来说,“king”这个回答也许就比前两个更高级。总之,每个模型都通过大量语料训练,它见过哪个词最常跟在哪个词后面,就预测它是接下来最可能被生成的词,这就是生成式模型的原理。
Yi:每次最多只能生成一个词吗?
徐昳昶:只能生成一个词。ChatGPT看起来能大段地说话,但它回答的内容也是一个词一个词生成的。只不过,它会在每生成一个词之后,就把这个词重新作为input(输入),去预测接下来最可能出现在后面的词。比如当它说出“He is a king”之后,king这个词就会反过来成为input的一部分,为继续生成下一个词作贡献。
Yi:这会不会造成说到哪儿是哪儿、看起来很连贯但并没有回答问题的状况?
徐昳昶:会存在这样的问题,我们叫做“长时间记忆缺失”。其实人一样会有这个问题,比如我说了一段话,有时候我后面说的跟前面说的,会在逻辑上完全不相关,原因就是我没有记住前面说的那么多东西。
AI有一样的问题,它的input长度同样有限制,因为过长的input会让AI算不过来。现在的ChatGPT之所以效果更好、语言更有逻辑、在多轮对话的时候上下文也更连贯,原因之一就是它有了更好的记忆能力,它能处理的input更长了。
Yi:更长的input、更好的记忆能力就能产生逻辑吗?
徐昳昶:表面上看,ChatGPT产生了一些逻辑上的连贯性。实际上,目前的这些AI仍然是深度学习模型,不具有所谓的逻辑推理能力,它们本质上还是基于统计在工作。它的逻辑、它所生成的单词和句子,都来自它曾经见过的语料。
ChatGPT的逻辑一方面来自它见过的语料中使用的逻辑,另一方面来自监督学习。GPT-3(注:OpenAI在ChatGPT之前推出的自然语言模型)的语料规模非常庞大,超过40T。而ChatGPT在GPT-3大规模语料训练的基础上,又增加了人为打标的监督学习。比如在机器生成答案后,ChatGPT的工程师会去审查那些答案,他们会给出答案哪里好、哪里不好的反馈,在ChatGPT回答的基础上修改其答案,使其更符合人的逻辑,再将答案反馈给ChatGPT去学习。实际上是对数据质量做了进一步优化。
Yi:这种监督学习如何穷尽用户可能问出的问题?
徐昳昶:它确实没办法穷尽,但这些有限的反馈数据是不是足够,是另一个问题。起码目前从ChatGPT的效果来看,这些有限的数据已经帮助它向应用级迈出了一步,而这一步已经让大家觉得它很好玩了。
Yi:需要什么程度的记忆力,才能达到ChatGPT现在的连贯性?
徐昳昶:虽然GPT能够记住(即在预测下一个词时input的长度)的信息长度已经比以前的模型更长了,但实际上也没有太长,大概2048个字。
这种长度与成本有关。成本的增长以平方级为单位,即长度每增长一倍,训练成本就有平方级的提高。最早的GPT和Bert(Google旗下的生成式模型)能够记忆和输入的长度都是512个字,现在能做到2048个,长度成长了4倍,训练成本就增长16倍。
Yi:
人是否也像这些模型一样用“predict the next word”的方式构建语言?
徐昳昶:现在模型说话方式和人说话本质上仍然是两种思维。人在说话的时候不会只想下一个词是什么,而是会想我下面的逻辑是什么,大概知道要说什么后,再去组织语言。不是像模型那样一个字一个字往外蹦,它甚至不知道它说的话连不连贯,所以可能产生很多废话文学。
Yi:这些模型是否加载了语言学家已经建构的人类语法?
徐昳昶:据我所知没有,生成式模型不能这么做。看似我们已经为我们的语言总结了很多规则,而且你认为这个规则肯定是对的,但如果把这样的死规则写到模型里面去,它就只会按照这个规则走,最后不能保证它生成出来的东西都是对的。
所以生成式模型所生成的结果都是由大量语料训练出来的,而不是因为人给它赋予了语言规则。哪怕是那些连接词、逻辑词,你认为它说得很有逻辑的部分,也都是因为它在大量语料里见过。它没有见过,就不能凭空生成。
大模型时代:参数竞赛
Yi:相较于其他生成式AI,GPT系列模型为什么表现更好?
徐昳昶:从GPT和Bert开始,业界第一次有了“大模型”这个概念。在此之前,所有的神经网络都比较小,没有多少参数量。GPT-1刚出现,参数量就上亿了。以前大家不知道参数这么多到底好不好。最早的神经网络只有2层,直到2012年的AlexNet有了5层神经网络,图像效果的确好一些,但大家不知道网络叠多深是好的。
到了GPT,GPT-1开始有12个block,你可以理解为12层,GPT-2有48个block,GPT-3叠到了96个。事实证明,它们确实大力出奇迹了。
Yi:大模型指的是网络层数多还是参数多?
徐昳昶:层数变多,参数自然就变多,每一层网络都有自己的参数。而要训练更深的网络,意味着要有更大的数据集,不然浅层的网络就已经能够把数据训练得够好。
所以GPT其实做了两件事,一来它把模型变得更大了,二来它用了更多更高质量的数据。你说从技术上它到底有没有突破?从框架上来说没有,它使用的仍然是深度学习。如果让我来做,我一样可以做,问题是我有没有那么多的数据,有没有那么多的算力,能不能拿到跟它一样好的结果,以及我要投多少钱进去。
Yi:
同样基于深度学习,在GPT使用的”predict the next word”之外有别的技术路径吗?
徐昳昶:Google的Bert和OpenAI的GPT走的是两条路。GPT走的是单向transform,而Bert的技术路径是双向transform。GPT是从前向后做单向预测,而Bert做的是完形填空。
比如“He is a man”这句话,中间抠掉“a”这个词,让你完形填空,这是Google的Bert在做的事。因为Google认为,“He is”和“man”都对“a”这个词有贡献。而GPT在看不到后面的“man”时就直接根据“He is”预测接下来的词是“a”了。GPT一直想要做的是生成式模型,所以它坚持走单向预测的路子,从GPT-1到GPT-3都是单向预测。
Yi:难道双向预测的效果没有单向预测好?
徐昳昶:其实最早双向的预测效果比单向好,理论上也是这样。但现在很难说到底谁好,因为各家模型越做越大,比如Bert一开始叠了24层神经网络,GPT-2就叠了48个,它们网络深度不一样。即使网络深度相同,也可以调整参数,只要参数变得更大,其实单向的效果也不差。所以很难说单向模型更好还是双向更好,目前还没有结论。
Yi:单向训练对算力的消耗会更少吗?
徐昳昶:不一定,看起来单向预测可以比双向预测少算一点,但实际训练要看对数据集的需求规模。单向训练可能需要比双向训练翻倍的数据量,才能让模型收敛。所以两种模型实际要用多少算力我们是不知道的。
商用:智能客服、搜索引擎、创意、代码助手?
Yi:
ChatGPT也被认为是一种聊天机器人,它跟很多互联网公司已经在使用的智能客服有什么不同?
徐昳昶:问答机器人很早就有了,问答机器人分为闭源的问答和开源的问答。闭源回答就是给定特定场景,用穷尽的方式列出可能被问的问题和答案。淘宝客服就属于这一种,它回答的大多数问题都跟它的生意有关,比如物流信息、产品还有没有货等,这些问题都有相应的参考答案。这种问答机器人可以回答的问题是有穷尽的,你不能问它业务之外的问题。
但GPT这类模型可以回答的问题是开放的,它什么都知道,也意味着它在特定领域上面一定不够专业,目前来看也是这样,没有办法商用。
Yi:这两类机器人所使用的技术有什么不同?
徐昳昶:淘宝客服等属于上一代聊天机器人,它们通过抓取问题中的关键词来识别问题。比如它们会构建客人最常问的30个问题,制作30个回答模板,然后将关键词对应的模板作为答案输出给用户,跟生成式模型是两回事。如果你的问题里有多个关键词,它就不一定抓得准。但这种聊天机器人可以商用,因为确实节约了很大部分人力。
Yi:ChatGPT可以有哪些商用场景?
徐昳昶:问题无法穷尽的场景就需要用GPT这种生成式模型来做。我认为它目前可能可以帮助一些初级文字工作者,当然不是说它生成的东西直接就可以使用,而是它确实能够提供一些思路。比如写个年终总结,或者设计个菜谱,它给出的东西不一定完全正确,但确实能给你一些思考。
但如果只是作为提供创意的system,一般个人也不太会为它付费,这也是个问题。其实GPT-3出来的时候,大家已经在问这个问题了。目前OpenAI仍然不能靠GPT来赚钱。
Yi:你认为它会取代搜索引擎吗?
徐昳昶:只要它还没有办法解决事实性错误这个问题,它就不能替代搜索引擎。原因很简单,当你去搜索一个东西,搜索引擎给出的大概率是非常相关的东西,且保证一定的准确性。比如搜索陈凯歌的作品,你搜出的结果一般不会出错,因为是人编辑好的。ChatGPT不行,有人试过,它可能会说张艺谋的什么作品是陈凯歌的。这种事实性错误它不能解决的话,就不能替代搜索引擎。
Yi:这跟它的语料是静态而非动态有关吗?
徐昳昶:可能有关系,更大的问题在于,在它的生成逻辑还是基于“predict the next word”的情况下,它自身没有办法对事情的对错作出判断。ChatGPT在官网也承认了这一点,负责给ChatGPT生成的文本打标签的人其实也不知道答案的对错,他们只能从文法结构上看出哪个更好,做出排序,但对于事实性错误也无法完全判断。
Yi:
Google旗下的Bert是否更有机会解决这个问题,比如将Google搜索引擎里的数据与Bert生成的答案做比较?
徐昳昶:暂时应该不会,它可能会用搜索引擎的结果去给Bert做一些提示,但不会通过Bert去直接展示结果。
问题不在于生成式模型与搜索引擎有不同的数据源,而在于它们本质上是架构不一样的两套东西。搜索本质是对已有数据的排序,匹配出与搜索词最相关的信息,而生成式模型基于神经网络。
Yi:
智能音箱出现的时候,就有人讨论过它们取代搜索引擎的可能性,生成式模型和这些智能音箱里的AI有什么区别?
徐昳昶:你问智能机器人问题的时候,其实它们只是把你问的问题转换成文字,然后去搜索引擎里搜索了一下,拿到答案后反馈给你的。这些AI更多是做了一个语音识别和文字转换的工作。如果你不联网,这些AI就什么都做不了。最典型的例子就是天气预报,ChatGPT做不了这样的预报,因为它不是一个天气预测模型。智能音箱里的AI可以给出第二天的天气,因为它通过搜索引擎去抓取了其他平台的天气预测数据。
反过来,如果你问那些智能音箱里的AI一个开放性问题,比如“你觉得某个音乐好不好听”,它可能也能生成一些反馈,但会比ChatGPT主观得多,因为模型不够大。
Yi:也有人认为ChatGPT未来可能取代程序员?
徐昳昶:在ChatGPT之前,Google就已经推出过所谓的自动补全式AI,专门给程序员使用,用以补全代码。它也用“predict the next word”的方式,一整段一整段地给出补全代码,就像你在ChatGPT里问了问题它回答一样。比如你跟这种写代码小助手说“你给我写个什么函数,这个函数满足哪些功能”,它就能给你生成一个满足你需求的函数。在一部分场景下它补全的已经不比人写得差了,所以它可以替代程序员的一部分初级工作。
找bug也是它可以完成的任务之一。就是当一个语言模型能够预测下一个词是什么的时候,它就可以通过对比它的预测和程序员的输入,如果两者不一样,它就可以初步判定是程序员错了。这类代码助手用了大量的代码做训练,所以它知道一行代码下面应该大概率接什么。
通用智能只有深度学习是不够的
Yi:
在人工智能的发展过程中,ChatGPT的进步有多大?怎么理解大家的兴奋?
徐昳昶:底层框架上面没有新进展,但在这套框架(指深度学习)上面往应用级还是进了一步的。从今年4月开始,整个AIGC(AI-Generated Content)领域不停有新东西产生,把整个社区带得非常火。这种进步是在模型的细节上有了新进展,应用了一个叫Diffusion Model(扩散模型)的算法,这个算法在2020年才被发表。
GPT-3出来的时候,有人说它给AI又续了5年到10年的命。因为AI领域确实有一段时间没有新东西出来了,ChatGPT有更好的效果,的确会给大家带来一些兴奋。但这种兴奋能持续多久还不确定。进步肯定是有,但没有那么大。
Yi:人工智能领域为什么长期难以有大的进步?
徐昳昶:影响AI进步的原因不只在于算法本身,也跟硬件有关。ChatGPT能有那么大算力,与硬件发展分不开。如果没有英伟达等硬件公司在显卡上面的优化,就无法支撑现在这些大模型的训练。ChatGPT放到5年前是训练不起来的,因为显卡不够。
深度学习其实也才是过去10年间的事情。深度学习的理论1980年代就有,但真正跑起来是在2012年。2015年开始,业界开始全面使用,到现在其实也没有几年。1980年代的神经网络还不叫深度学习,因为不deep,只有2层。后来大家发现,叠得越深,效果越好,直接就开启了一个新时代。
Yi:
一种观点认为深度学习领域也存在摩尔定律,每增加一个级别的训练数据,模型的表现就会上一个台阶,那么当可用以训练的数据量见顶的时候,AI还可以如何成长?
徐昳昶:有两条路,一条路是去研究现在的模型是不是真的足够大了(注:指神经网络的层数和参数更多),这是一个问题。当年GPT-1出现的时候,已经有了上亿参数,我们觉得已经够大了。后来的事实告诉我们,模型还可以更大,GPT-2出来的时候参数数量达到10亿个,你觉得它不能更大的时候,GPT-3的参数达到了千亿级别,GPT-4会不会有万亿个参数不知道。这是一条路,就是把模型不停加大,花钱就能有更好的效果。
还有一条路,是彻底推翻深度学习,改用别的算法。但新算法到底在哪里,现在还不清楚。学界还在探索新算法,包括原来所谓的深度学习三巨头(注:Hilton、LeCun和Bengio,因在深度学习上的贡献,获得2018年的图灵奖),他们也在寻找比深度学习更好的算法。比如LeCun就认为,深度学习本质还是梯度回传(指梯度下降+反向传播),而他认为梯度回传不是最终的解决方案。
也有人认为,深度学习在方向上是对的,但是需要在理论上再做一些突破。否则我们只能不停扩大模型、增加算力。
Yi:生成式模型在生成文字、图片、视频等不同内容时的技术有何不同?
徐昳昶:不太一样,生成图片不是像文字那样一个字一个字、一个像素一个像素生成的。它是一整张图片直接生成的,只不过中间有很多步骤,第一步先生成一张比较模糊的图片,然后不断去噪,把图片一步一步具象化。它不是把不同关键词对应的最可能图片叠加在一起实现的,大家一开始看到成果的时候以为它们这么做,但实际上不是。它使用的是Diffusion Model(扩散模型)算法,这个算法在2020年才被发表。
Yi:是否存在一个可以生成各种类型内容的通用型AI?
徐昳昶:目前还有些困难,但不保证ChatGPT做更多训练之后能做这件事。现在你让ChatGPT去生成一些图片,它好像也能做到。
Yi:那深度学习的神经网络模型是否一定越大越好?
徐昳昶:并不是越大越好。它可能到某个程度就好了,把这个程度确定出来,大家就可以照着这个程度去训练。但哪个规模的模型是最好的,还不知道,这个也是业界探究的方向之一。
Yi:是否照着人脑神经网络的规模去构建最好?
徐昳昶:问题是人的大脑神经元还是比目前已有模型的参数量多的。所以也有一派研究者说,人工智能神经网络要大到跟一个人脑参数量一样的规模,才能智能起来。到底对不对,也还不知道。
Yi
:即刻是一个做社交产品的公司,你担不担心这种智能的聊天机器人未来取代你们的产品?
徐昳昶:它会不会替代社交,我个人认为不一定,就它目前的能力还达不到。目前整个AI领域都还处于弱人工智能阶段,离强人工智能还有比较远的距离。
起码在深度学习的框架下,还不能实现这个事情。AI可能会随着训练语料增多,生成的东西越来越接近于我们给它看到的东西。因为它见过的东西肯定比人多很多,一个人只能看到世界的一部分,模型能看到更多,那么它给你生成的内容可能会让你觉得新鲜。但它仍然没有形成人的逻辑和情感,这是人不可替代的地方。
Yi:
很多人认为这些模型之所以回答问题回答不好,是因为它自己都不理解它在说什么,“理解”对实现机器智能来说重要吗?
徐昳昶:我个人理解,理解这个东西对机器不是很重要,目前的框架(指深度学习)对机器来说不存在理解这个东西。对机器来说,它只是在拟合对标。哪怕它做得好的时候,也只是因为它在训练数据中见过,而不是它理解了。
Yi:既然我们已经可以在深度学习的框架上加上注意力模块和记忆模块,为什么不再加上个理解模块呢?
徐昳昶:如果我们知道怎么去实现它,应该就去实现它了。目前我们在理论上还没有实质性进展。