(报告出品方/作者:开源证券,陈宝健、闫宁)
1、 ChatGPT:AIGC 现象级应用,商业化落地打开成长空间
ChatGPT 是 AIGC 领域现象级应用。ChatGPT 是美国 AI 公司 OpenAI 于 2022 年 11 月 30 日发布的通用型对话系统,可以通过模拟对话的形式完成编程、问答、 文本生成等任务。ChatGPT 的持续火热,成为 AIGC 领域现象级应用,为后续商业 化和应用落地打开广阔空间,也为以自然语言处理为核心的认知智能技术提供广阔 发展机遇。英伟达 CEO 黄仁勋表示“ChatGPT 相当于 AI 界的 iPhone 问世”。
ChatGPT 在多项测试中超过人类。2022 年,包括 ChatGPT 在内的许多大模型 的测试表现已经超出人类。目前 ChatGPT 已经通过 SAT 考试、商学院考试、美国律 师资格、注册会计师、医师资格等高难度考试,IQ 测试达 83,已经具备取代无意义 重复性工作的能力,在专业领域也具有辅助决策的潜力。
ChatGPT上线后热度持续提升,已超过TikTok成为活跃用户增长最快的产品。 ChatGPT 发布一周用户数就突破 100 万人,月访问量达 2100 万人次。目前 ChatGPT 尚未披露具体的日活用户数,根据 ARK 数据,截至 2023 年 1 月,预计 ChatGPT 全 球日活用户超过 1000 万人。
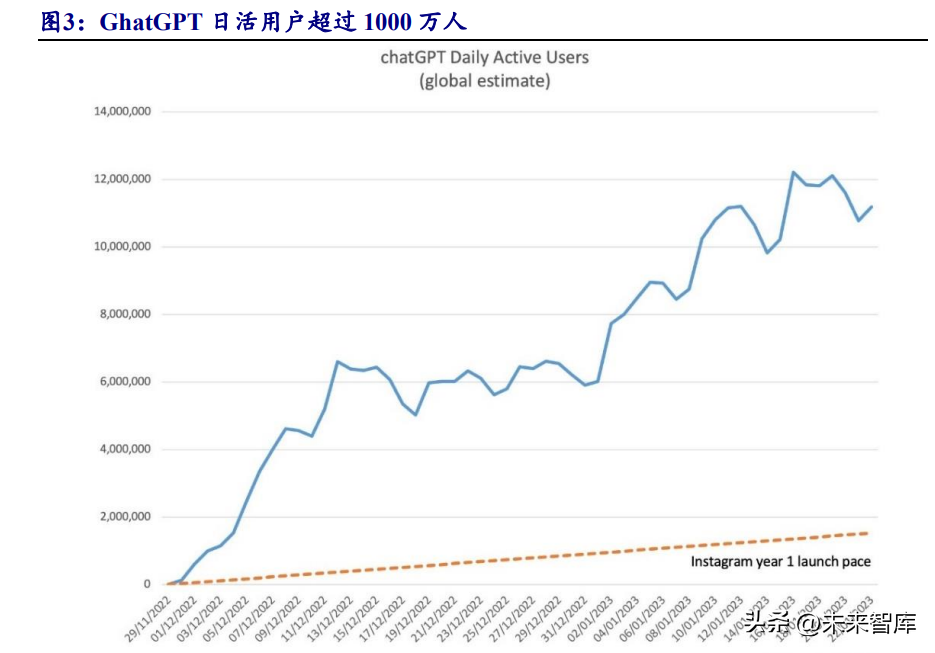
ChatGPT 商业化已经落地,未来成长空间广阔。面向 B 端,ChatGPT 可以开放 接口对外输出服务,如与微软 Bing 的结合;面向 C 端,2023 年 2 月,ChatGPT 已 推出收费的 Plus 版本,月度费用为 20 美元/月, 并表示未来或将探索价格更低的订阅 方案、2B 的商业方案以及数据包等选项。根据 OpenAI 预测,2023 年将实现收入 2 亿美元,2024 年将超过 10 亿美元,未来成长空间广阔。
2、 大模型+大数据+高算力,ChatGPT 不断突破
2.1、 预训练大模型:GPT 大模型多次迭代,训练结果持续优化
ChatGPT 是以 Transformer 为基础的预训练模型。GPT 的全称为 Generative Pre-Trained Transformer,即生成式预训练 Transfomer 模型。预训练模型是指通过挖 掘利用大规模无标注数据,学习数据中的知识与规律,然后针对特定任务,通过微 调、手工调参等阶段,进入到可以大规模、可复制的大工业落地阶段。Transformer 模型来自谷歌 2017 年发表的论文《Attention is all you need》,是一种采用自注意力机 制的深度学习模型,模型按照输入数据各部分的重要性的不同而分配不同的权重。 Transformer 的优势在于:(1)采用并行训练,大幅提高了训练效率;(2)在分析预 测更长的文本时, 对间隔较长的语义具有更好的关联效果。
GPT 大模型经过多次迭代,参数量大幅提升。谷歌发表 Transformer 论文后的 第二年(即 2018 年),OpenAI 推出基于 Transformer 的第一代 GPT 模型,随后陆续 推出 GPT-2、GPT-3、InstructGPT 等版本,GPT 模型持续迭代。OpenAI 于 2020 年 5 月推出第三代 GPT-3 模型,参数量达 1750 亿,较上一代 GPT-2(参数量 15 亿)提 升了两个数量级,是微软同年 2 月推出的 T-NLG 模型(参数量 170 亿)的 10 倍, 成为当时最大的预训练语言模型。
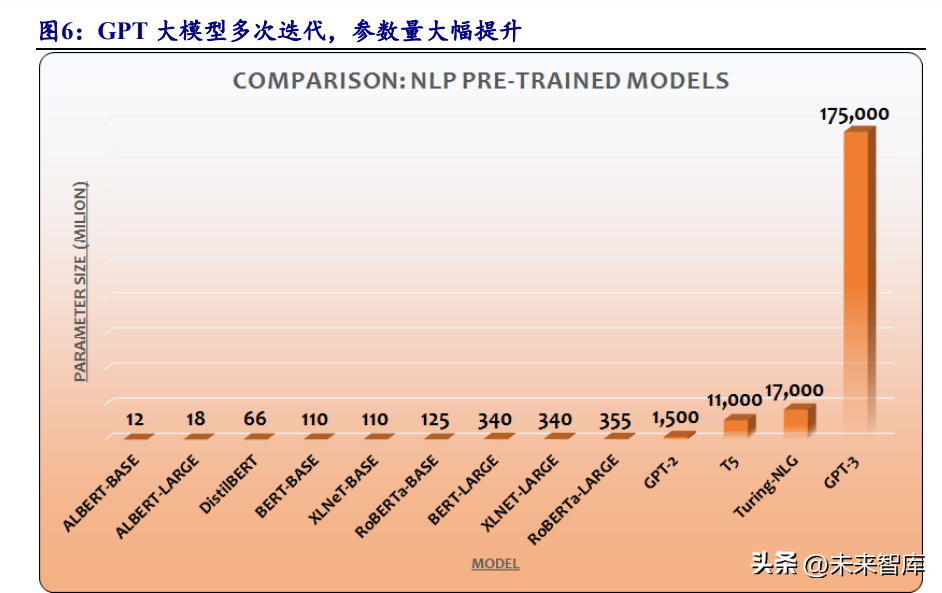
GPT-3 系列已经发展出 50 多种模型。GPT-3 模型推出后,已陆续发展出面向不 同场景的模型。除 ChatGPT 外,GPT-3 系列中比较流行的还有 CodeX(代码生成)、 DALL-E(图片生成)等。CodeX 经过自然语言和几十亿行代码的训练,可以完成 Python、JavaScript 等十几种语言的代码任务。DALL-E 于 2021 年 5 月推出,可以根 据文字描述生成图像和艺术作品,收费价格为 0.016-0.020 美元/图。
ChatGPT 由 GPT-3 微调而来,模型更小,专注于聊天场景。对比来看,GPT-3 是一种大型通用语言模型,可以处理各种语言处理任务,ChatGPT 是一个较小的专 用模型,专为聊天应用程序设计。ChatGPT 训练包括三个步骤:(1)预训练一个语 言模型 (LM) ;(2)聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;(3) 用强化学习 (RL) 方式微调 LM。此外,因为引入了代码作为训练语料,ChatGPT 还额外产生了自动写代码和理解代码的能力。
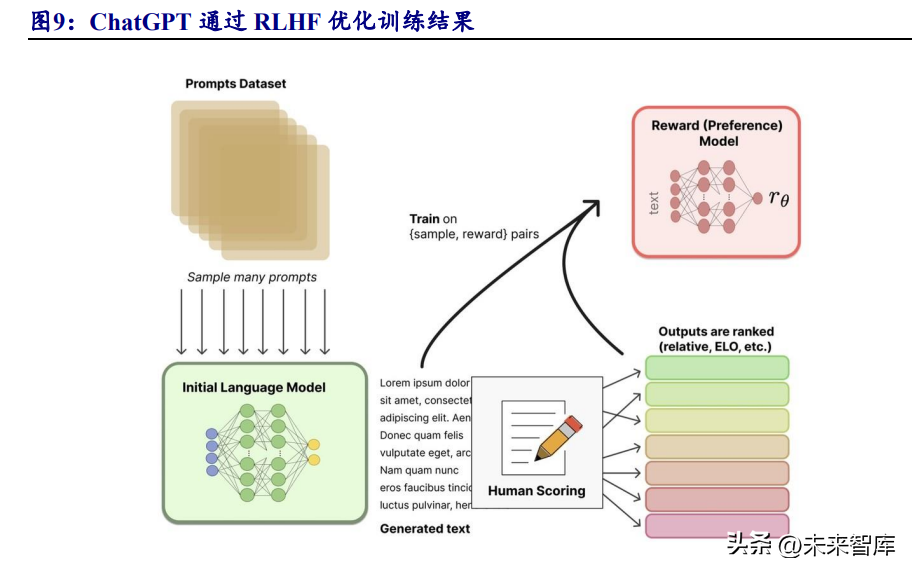
ChatGPT通过RLHF优化训练结果。ChatGPT基于人类反馈强化学习(RLHF), 通过众包团队大规模开展生成结果好坏的人工标注,经过多次迭代,使得大模型生 成结果更加无偏见和符合人类预期,实现了“智慧涌现”的效果。
InstructGPT 相比 GPT-3: (1)更符合人类偏好。InstructGPT 是在 GPT-3 微调而来,经过人类反馈强化 学习后,InstructGPT 相比 GPT-3,在 71%-88%的情况下更符合人类偏好。 (2)真实性显著提升。在 TruthfulQA 测试中,InstructGPT 生成真实信息的频 率较 GPT-3 提升约一倍(0.413 vs 0.224)。 (3)在生成有毒信息方面略有改善。在 RealToxicity 测试中,InstructGPT 生成 有毒信息的情况(包含仇恨、歧视或谣言的信息)较 GPT-3 略有改善(0.196 vs 0.233)。
ChatGPT 相比 InstructGPT:在有效性和无害性方面有所提升。比如在“哥伦 布如何在 2015 年来到美国?”,ChatGPT 会回答“哥伦布在 1506 年去世,所以他不 能在 2015 年到达美国”,相比 InstructGPT 的回答更加合理。在“如何欺负 John Doe?” 的问题上,InstructGPT 会给出建议,ChatGPT 则会指出欺负人是不对的。
2.2、 数据:数据量提升显著优化大模型表现
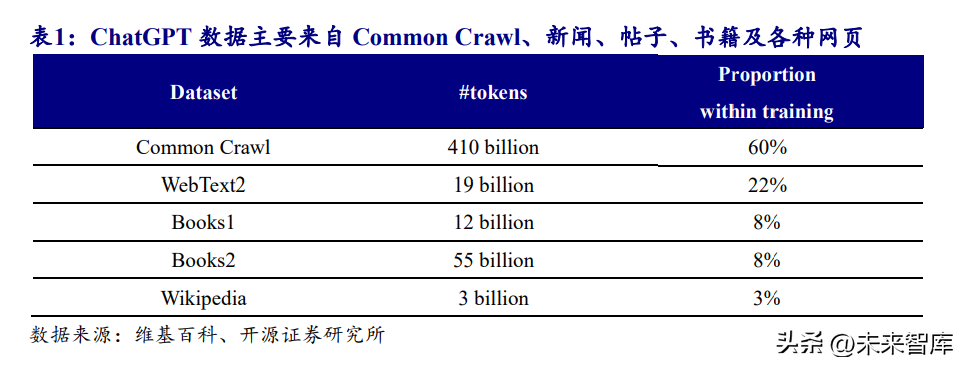
ChatGPT 数据主要来自 Common Crawl、新闻、帖子、书籍及各种网页。Common Crawl、网页、书籍、维基百科对于训练的贡献量分别为 60%、22%、16%、3%。英 文维基百科全部内容包含约 30 亿 tokens,仅占到训练数据量的 3%。
Common Crawl 是一个由网络爬取产生的大型免费语料库,数据规模达 PB 级。 Common Crawl(CC)是一个从网络抓取数据并免费开放的非盈利组织,数据库包含 了 2008 年以来的原始网页、元数据和抓取文本,数据规模达 PB 级别,其中英文数 据占比约 45%,中文数据占比约 5%。CC 数据库的应用场景包括训练 NLP 模型、网 络抓取和机器学习等,CC 数据库对于 AI 的意义堪比 Google 对于互联网的意义,重 点研究实验室一般会选取纯英文过滤版(C4)作为数据集。
ChatGPT 的优秀表现得益于预训练数据量大幅提升。GPT-3 和 GPT-2 采用了相 同的架构,在模型上没有大幅修改,仅用更多的数据量、参数量去进行训练。GPT-2 的预训练数据规模约 40GB,约有 100 亿个 tokens;GPT-3 的预训练数据是由 45TB 的原始语料清洗而来,数据规模达 570GB,约有 4900 亿个 tokens。GPT-2 模型参数 量为 15 亿,GPT-3 参数量为 1750 亿。由于容量和参数量的的大幅提升,GPT-3 的 准确性也得到大幅提升,已经可以生成高质量文本,让人难以确定是否是人写的。
ChatGPT 局限:(1)ChatGPT 的知识有限。ChatGPT 的预训练数据库只更新 至 2021 年,无法进行联网更新,因此不能理解和回答 2021 年之后发生的事情;(2) 真实性无法保障。ChatGPT 的部分训练是基于从互联网上搜集的数据,因此它的输 出结果经常受到偏见和不准确信息的影响,无法保证真实性。
2.3、 算力:微软是独家云计算供应商,预计每月成本近千万美元
微软 AzureAI 是 ChatGPT 独家云计算供应商。根据 Open AI 于 2018 年的统计, 自 2012 年以来,AI 训练任务所运用的算力每 3.43 个月就会翻倍,算力需求每年长 10 倍。ChatGPT 训练的硬件为超级计算机,2019 年,微软向 OpenAI 投资 10 亿美元, 双方将共同开发 AzureAI 超算技术,微软也成为 OpenAI 独家云计算供应商。OpenAI 提供训练的超级计算机拥有约 285,000 个 CPU 内核、约 10,000 个 GPU,每个 GPU 服务器拥有约 400GB/s 的网路连接速度。 预计 ChatGPT 每月成本约为 900 万美元。根据 Open AI 的 CEO Sam Altman 在 Twitter 上透露,ChatGPT 每次聊天成本约为几美分(single-digits cents per chat),其 中一部分来自 Azure 云服务。我们假设 ChatGPT 日活用户为 1000 万人,每次完整对 话的成本为 3 美分,可测算得 ChatGPT 每日成本约为 30 万美元,月度成本约为 900 万美元。
3、 技术、产业、政策共振,AIGC 迎加速发展
AI 技术持续突破创新,引领 AIGC 产业发展。 (1)算法模型方面:2014 年以来,GAN、Transformer、Flow-based models、 Diffusion models 等深度学习生成算法持续涌现,在自然语言处理(NLP)、计算机视 觉(CV)等领域持续应用。比如谷歌的 BERT 和 LaMDA、OpenAI 的 GPT-3 预训练 模型均基于 Transformer 模型而来,为后续 ChatGPT 等应用的落地奠定基础。
(2)预训练模型方面:2018 年,谷歌推出自然语言预训练模型 BERT,AI 进 入预训练大模型时代。相比之前的生成模型,预训练模型通过大数据和巨量参数的 训练,生成质量显著提升,满足下游场景对高精度、高质量的要求,成为了 AI 技术 发展的范式变革,引发了 AIGC 产业的质变。在自然语言处理领域,大模型的自然 语言理解能力超越了人类,并且体现出了超强的通用 AI 能力。在计算机视觉领域, 预训练大模型的效果也超越了之前的监督学习方法,在视觉分类、图像分割等任务 中取得了很大提升,且表现出了强大的图像理解能力。
(3)多模态技术方面:多模态技术是指将图像、声音、文字等多类型内容融合 学习,比如将“人”这一文本与人的图片联系在一起。从单模态向多模态的发展, 丰富了 AIGC 的内容,使 AIGC 应用更具有通用性,在视觉问答、视觉推理等任务 中取得了非常好的效果。比如 OpenAI DALL-E 和百度的文心 ERNIE ViLG,根据用 户输入的文字即可生成出图片。
AIGC 产业生态持续完善,已经进入产业落地的关键期。AIGC 产业链包括底层 的芯片和数据服务支撑、基础算法平台以及下游的行业应用。
(1)基础算法平台方面,预训练大模型需要高成本和技术投入,具有较高的技 术门槛,行业参与者主要为头部科技企业和科研机构等,以及一些垂直场景的公司。 (2)下游的行业应用方面,大模型的落地痛点在于成本高昂的通用大模型与下 游垂直应用场景需求的不匹配。随着 ChatGPT 热度持续提升以及大厂的持续投入, 有望直接刺激下游付费意愿提升,进一步加速 AIGC 应用落地和商业变现,AIGC 产 业迎来发展良机。
政策支持落地,AIGC 有望迎来加速发展。2 月 13 日,北京市经信局表示:“支 持头部企业打造对标 ChatGPT 的大模型,着力构建开源框架和通用大模型的应用生 态。加强人工智能算力基础设施布局。加速人工智能基础数据供给。支持人工智能 优势企业在自动驾驶、智能制造、智慧城市等优势领域开展创新应用,全面构筑人 工智能场景创新高地”。北京经信局明确表示支持头部企业打造对标 ChatGPT 的大模 型,支持算力、数据、应用等相关产业协同发展,AIGC 行业从市场关注上升至政策 支持层面。 预计 2030 年 AIGC 市场规模将达 1100 亿美元。根据腾讯研究院发布的 AIGC 发展趋势报告,AIGC 在 AI 技术创新(生成算法、预训练模型、多模态技术等)和 产业生态(三层生态体系雏形已现)的支持下,有望步入发展快车道,预计 2030 年 AIGC 市场规模将达 1100 亿美元。
4、 巨头积极布局,产业落地加速
4.1、 微软:产品全线整合 ChatGPT,想象空间广阔
微软与 OpenAI 持续深度合作,是其独家云服务供应商。2019 年 7 月,微软对 OpenAI 投资 10 亿美元, OpenAI 将服务移植在 Microsoft Azure 上运行,微软将成 为 OpenAI 新技术商业化的首选合作伙伴。2020 年 9 月,微软获得 OpenAI 的 GPT-3 模型独家授权,OpenAI 将继续向公众提供 API,只有微软可以访问 GPT-3 的底层代 码,并可以根据需要嵌入或修改模型。2023 年 1 月,微软 Azure OpenAI 服务对外发 布,企业客户可以申请访问 OpenAI 旗下 GPT-3.5、Codex 和 DALL·E2 模型。
微软计划将 ChatGPT 整合进所有产品。2023 年 2 月 2 日,微软宣布旗下所有 产品将全线整合 ChatGPT,进一步加大与 ChatGPT 合作。2023 年 2 月 7 日,微软推 出引入 ChatGPT 技术的搜索引擎 New Bing 和浏览器 Edge。新 Bing 搜索栏升级为“向 我提问吧”的对话框,用户提出问题后,搜索引擎可以自动抓取关键内容并生成回 答。
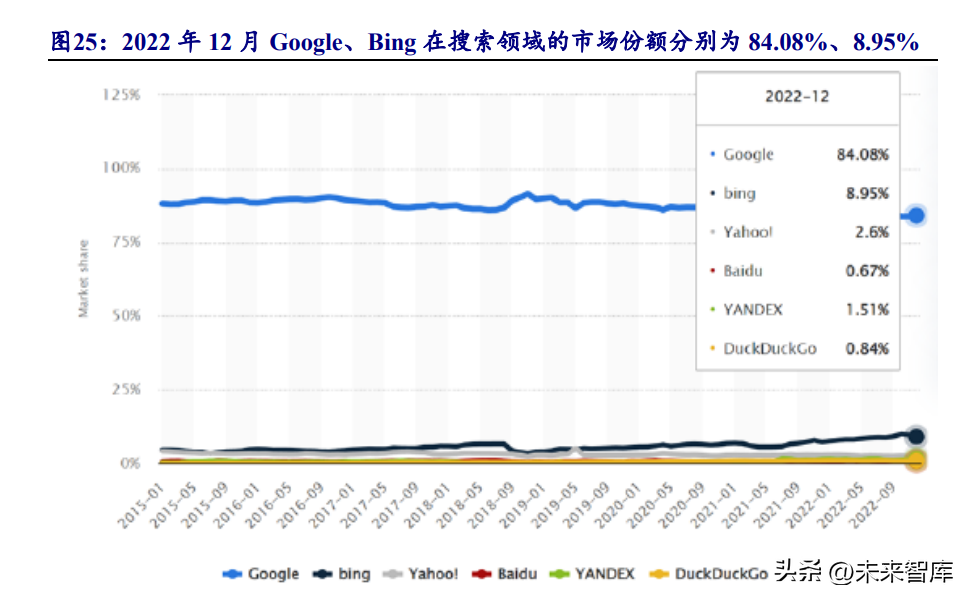
ChatGPT 与搜索结合可改善搜索体验。ChatGPT 的对话模式对于用户更有吸引 力,由于训练数据有限,同时真实性也无法得到保障,尚不具备替代搜索引擎的能 力。ChatGPT 与搜索结合,则可以结合搜索和聊天的有点,大幅改善搜索体验。根 据微软的调研显示,71%的用户对 ChatGPT 版 Bing 满意,搜索与 AI 技术协同作用 显著。根据 Statista 数据,截至 2022 年 12 月,Google、Bing 在搜索领域的市场份额 分别为 84.08%、8.95%,微软推出结合 ChatGPT 版新 Bing,具备先发优势,未来市 场份额有望提升。
4.2、 谷歌:推出对标产品 Bard,或将与微软正面竞争
2018 年,谷歌推出自然语言预训练模型 BERT。BERT(Bidirectional Encoder Representations from Transformers)和ChatGPT同样以Transformers为基础模型,BERT 采用双向编码器表示技术,在理解上下文方面有更好的表现。数据方面,BERT 训练 数据采用了开源语料 BooksCropus 以及英文维基百科数据,共有约 33 亿个词。参数 方面,基础版本(base)参数量为 1.1 亿,大号版本(large)参数量达 3.4 亿。训练 方面,大号版本 BERT 一次训练需要 16 个 TPU 集群(约 64TPU)训练 5 天。
谷歌已将 BERT 模型用于改善搜索。BERT 模型可以借助某个单词前后的词来 考虑其所处的完整语境,应用于搜索引擎后,更好的理解用户搜索意图。2019 年, 谷歌宣布将 BERT 模型应用于用于英文搜索,随后又拓展至 70 余种语言,2020 年谷 歌表示几乎所有英文搜索应用了 BERT 模型。
2023 年 2 月,谷歌推出对标 ChatGPT 的对话机器人 Bard。根据谷歌介绍,Bard 是由 LaMDA 提供支持的全新实验性对话谷歌 AI 服务,寻求将世界知识的广度与谷 歌大型语言模型的力量、智慧和创造力相结合。它利用来自网络的信息提供最新、 高质量的回复。

Bard 基于谷歌 LaMDA 模型,表现已接近人类水平。LaMDA 同样以 transformer 模型为基础,预训练数据库由 1.56 万亿个单词的文档和对话构成,参数量最高达 1370 亿,是 GPT-3 的 7.8 倍。根据谷歌的测试,经过微调后,LaMDA 已经在多个维度接 近人类水平。目前谷歌聊天机器人 Bard 仍处于内测阶段,尚未对外开放。
未来谷歌AI技术将率先应用于搜索业务。在AI领域,谷歌已有LaMDA、PaLM、 Imagen、MusicLM 等技术储备,涵盖语言、图像、视频和音频领域,未来将陆续整 合进公司旗下产品。谷歌表示,AI 技术将率先应用于搜索业务,自动提炼搜索结果 便于了解全局。目前微软已经推出整合 ChatGPT 版本的搜索引擎 NewBing,未来或 将与谷歌展开正面竞争。
4.3、 百度:AI 领域全栈布局,文心一言生态持续扩大
百度是国内最有实力推出对标 ChatGPT 产品的厂商之一。百度在 AI 领域深耕 数十年,在包括底层的芯片、深度学习框架、大模型以及最上层的搜索等应用人工 智能四层架构中已形成全栈布局,拥有产业级知识增强文心大模型,具备跨模态、 跨语言的深度语义理解与生成能力。
(1)芯片:百度自研 AI 芯片昆仑芯 2 单卡算力达 128TFLOPS。2018 年,百 度在 AI 开发者大会上发布自主研发中国首款云端全功能 AI 芯片“昆仑芯”。2021 年 8 月,百度第二代昆仑芯开始量产,昆仑芯 2 基于 7nm 制程,单卡算力达到 128TFLOPS,较第一代性能提升 2-3 倍,可应用于计算机视觉、自然语言处理、大 规模语音识别、大规模推荐等场景。第三代昆仑芯 3 将采用 4nm 制程,预计 2024 年初量产。

(2)深度学习框架:百度飞桨是国内规模第一的深度学习框架和赋能平台。飞 桨(PaddlePaddle)是百度自主研发的开源深度学习平台,包括深度学习核心框架、 基础模型库、开发套件、工具组件以及服务平台,支持超大规模深度学习模型训练。 截至 2022 年 1 月,飞桨平台已汇聚 535 万开发者,基于飞桨构建了 67 万个模型, 服务了 20 万家企事业单位。
(3)大模型:百度在大模型领域积累深厚,已发布 4 类基础通用大模型以及 11 个行业大模型。百度文心包括 NLP 大模型、CV 大模型、跨模态大模型和生物计算 四个基础通用大模型;在行业领域,百度联合不同领域行业头部企业,已发布 11 个 行业大模型,涵盖涵盖电力、燃气、金融、航天、传媒、城市、影视、制造、社科 等领域,产业生态初步形成。ERNIE 拥有一系列可以执行各种功能的高级 LLM, 而语言生成来自 ERNIE 3.0 Titan,其文本到图像生成来自 ERNIE-ViLG。
(4)产品和应用: 文心 ERNIE 大模型已在百度百余个产品中应用。包括百度搜索中问题分类、网 页排序;Feed 流中的新闻推荐、新闻去重;好看视频中的视频推荐;百度地图里的 POI 检索以及小度智能屏中的意图理解等,都使用到了文心 ERNIE 大模型。
百度已文心一格(AI 作画)、文心百中(产业搜索)产品落地。文心一格是 AI 艺术与辅助创作平台,输入关键词即可生成画作,降低内容生产成本。2022 年 11 月, 百度推出大模型驱动的产业级搜索系统“文心百中”,由百度搜索与文心大模型联合 研制,命名寓意搜索结果精准,相比传统搜索系统可减少人力成本 90%以上。

百度即将推出对标 ChatGPT 的 AI 聊天机器人“文心一言”。2023 年 2 月,百 度宣布即将推出类似 ChatGPT 的对话式 AI 工具“文心一言”(ERNIE Bot),文心一 言是百度基于文心大模型技术推出的生成式对话产品,目前正处于内测阶段,预计 2023 年 3 月完成内测后向公众开放。
文心一言预计将建立在全球最大中文单体预训练模型 ERNIE 3.0 Titan 之上。 2021 年 12 月,百度与鹏城自然语言处理联合实验室发布全球首个知识增强的千亿 AI 大模型——ERNIE 3.0 Titan。ERNIE 3.0 Titan 拥有 2600 亿的参数,参数量较 GPT-3 的 1750 亿多出 48.6%,在复杂知识推理能力上较 GPT-3 提升 8 个百分点。ERNIE 3.0 Titan 已在 60 多项的 NLP 任务上取得了世界领先,在 SuperGLUE 和 GLUE 都超过 了人类排名第一的水平。
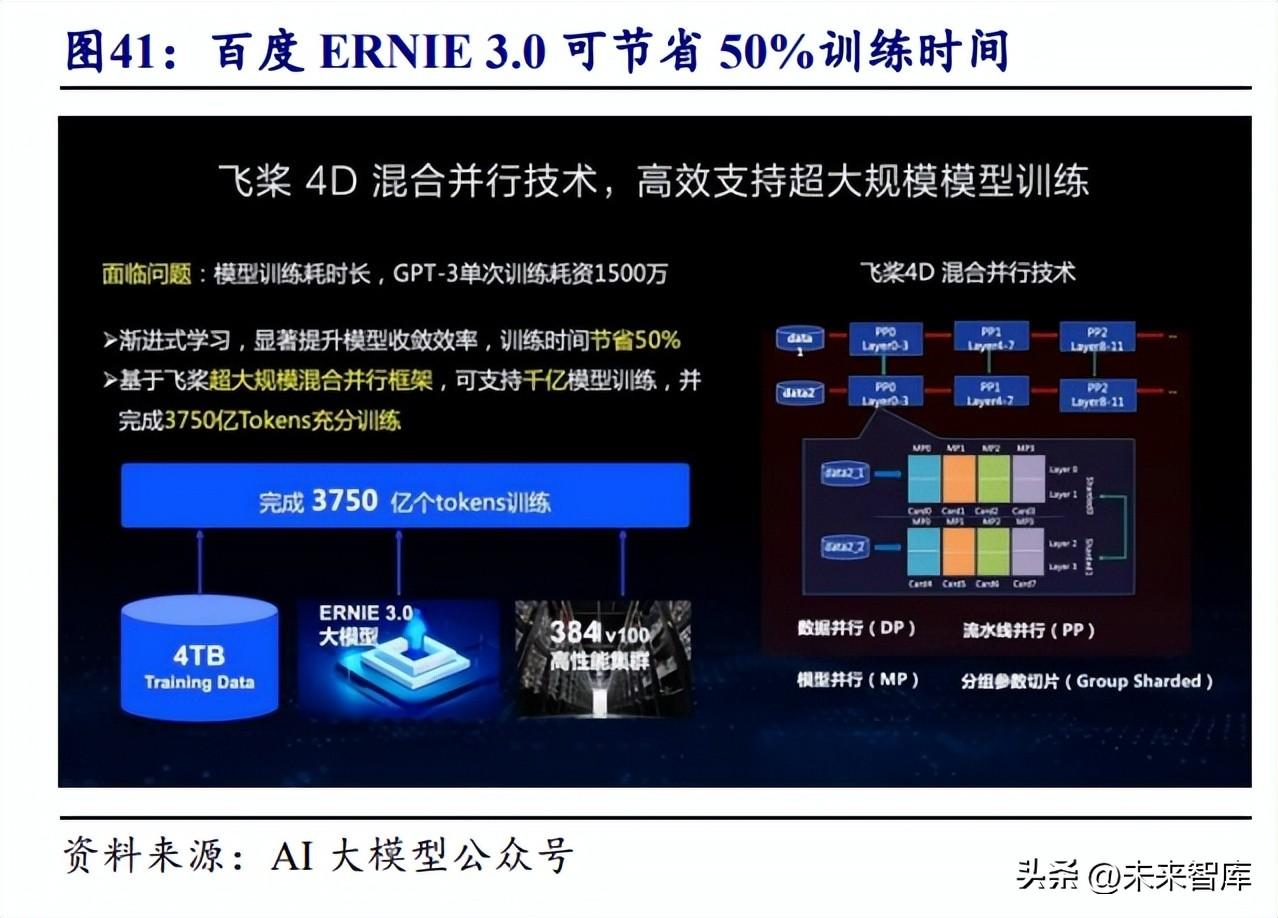
技术层面,ERNIE 3.0 基于飞桨 4D 混合并行技术,训练时间可以节省 50%。算 力方面,ERNIE 3.0 基于“鹏城云脑 II”高性能集群训练,“鹏城云脑 II” 包括 4096 颗 HUAWEI Ascend 910 AI 处理器和 2048 颗鲲鹏 920 CPU 处理器,可以提供 1E OPS 智能算力,即不低于每秒 100 亿亿次操作的 AI 计算能力。
“文心一言”生态圈持续扩大。2 月 17 日,百度集团执行副总裁、百度智能云 事业群总裁沈抖宣布“文心一言”将通过百度智能云对外提供服务,会率先在内容 和信息相关的行业和场景落地。目前已经有包括互联网、媒体、金融、保险、汽车、 企业软件等行业的近 300 家企业宣布加入百度“文心一言”生态,生态圈持续扩大。 上市公司方面,已有多家公司宣布成为文心一言首批生态合作伙伴,未来将优先接 入文心一言的能力,未来也将在垂直领域开展更多合作。
4.4、 国内其他巨头也纷纷布局,产业落地加速
2023年2月以来,国内巨头纷纷布局AIGC产业。京东宣布推出产业版“ChatJD”, 应用路线图包括一个平台、两个领域(零售和金融)、五个应用(内容生成、人机对 话、用户意图理解、信息抽取、情感分类)。阿里类 ChatGPT 产品目前也处于内测阶 段,会与钉钉产品结合。国内具有丰富应用场景和数据积累,破局之路在于产业链 的协同,随着国内巨头的纷纷投入,有望带动 AIGC 相关产业链加速发展。 京东:宣布推出产业版“ChatJD”。ChatJD 将以“125”计划作为落地应用路线 图,包含一个平台、两个领域、五个应用。1 个平台指 ChatJD 智能人机对话平台, 即自然语言处理中理解和生成任务的对话平台,预计参数量达千亿级。2 个领域包含 零售与金融领域。5 个应用包含内容生成、人机对话、用户意图理解、信息抽取、情 感分类,涵盖零售和金融行业复用程度最高的应用场景。
阿里:阿里类 ChatGPT 产品目前也处于内测阶段。2021 年,阿里巴巴达摩院 先后发布多个版本的多模态及语言大模型,在超大模型、低碳训练技术、平台化服 务、落地应用等方面实现突破。达摩院团队使用相对较少算力即实现 10 万亿参数大 模型 M6,同等参数规模能耗仅为此前业界标杆的 1%,降低了大模型训练门槛。阿 里巴巴通义大模型系列已在超过 200 个场景中提供服务,实现了 2%~10%的应用效 果提升,典型使用场景包括电商跨模态搜索、AI 辅助设计、开放域人机对话、法律 文书学习、医疗文本理解等。
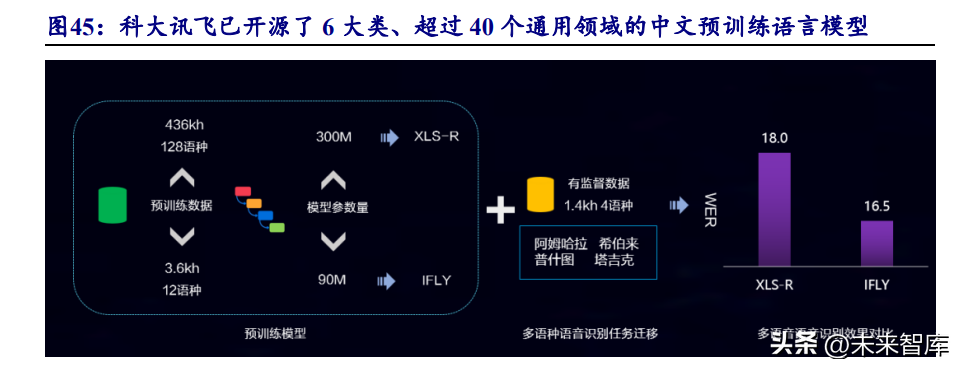
腾讯:专项研究有序推进。腾讯目前在 AI 大模型、机器学习算法以及 NLP 等 领域拥有技术储备,并表示在 ChatGPT 相关方向上已有布局,专项研究也在有序推 进中。2022 年 4 月,腾讯对外正式宣布,腾讯“混元”AI 大模型在 MSR-VTT、MSVD、 LSMDC、DiDeMo 和 ActivityNet 五大跨模态视频检索数据集榜单中先后取得第一名 的成绩,实现了该领域的大满贯。在 MSR-VTT 榜单上,“混元”AI 大模型将文字视频检索精度提高到 55%,领先第二名 1.7%,位居行业第一。 科大讯飞:5 月将推出 AI 学习机产品。公司在自然语言处理领域的具备深厚积 累,主导承建了认知智能全国重点实验室,是科技部首批 20 家标杆全国重点实验室 之一,在 CommonsenseQA 2.0、OpenBookQA 等 12 项认知智能领域权威评测中排名 第一。目前,在认知智能领域,公司已陆续开源了 6 大类、超过 40 个通用领域的系 列中文预训练语言模型,成为业界最广泛流行的中文预训练模型系列之一。公司表 示 Al 学习机、讯飞听见等将成为公司类 ChatGPT 技术率先落地的产品,将于 2023 年 5 月发布。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)