“U-Net已死,Transformer成为扩散模型新SOTA了!”
就在ChatGPT占尽AI圈风头时,纽约大学谢赛宁的图像生成模型新论文横空出世,收获一众同行惊讶的声音。
△MILA在读ML博士生Ethan Caballero
论文创意性地将Transformer与扩散模型融合,在计算效率和生成效果上均超越了基于U-Net的经典模型ADM和LDM,打破了U-Net统治扩散模型的“普遍认知”。
网友给这对新组合命名也是脑洞大开:
All we need is U-Transformer
希望他们没有错过Transffusion这个名字。
要知道,这几年虽然Transformer占尽风头,但U-Net在扩散模型领域仍然一枝独秀——
无论是“前任王者”DALL·E2还是“新晋生成AI”Stable Diffusion,都没有使用Transformer作为图像生成架构。
△英伟达AI科学家Jim Fan
如今新研究表明,U-Net并非不可用Transformer替代。
“U-Net并非不可替代”
论文提出的新架构名叫Diffusion Transformers(DiTs)。
架构保留了很多ViT的特性,其中整体架构如图左(包含多个DiT模块),具体的DiT模块组成如图右:
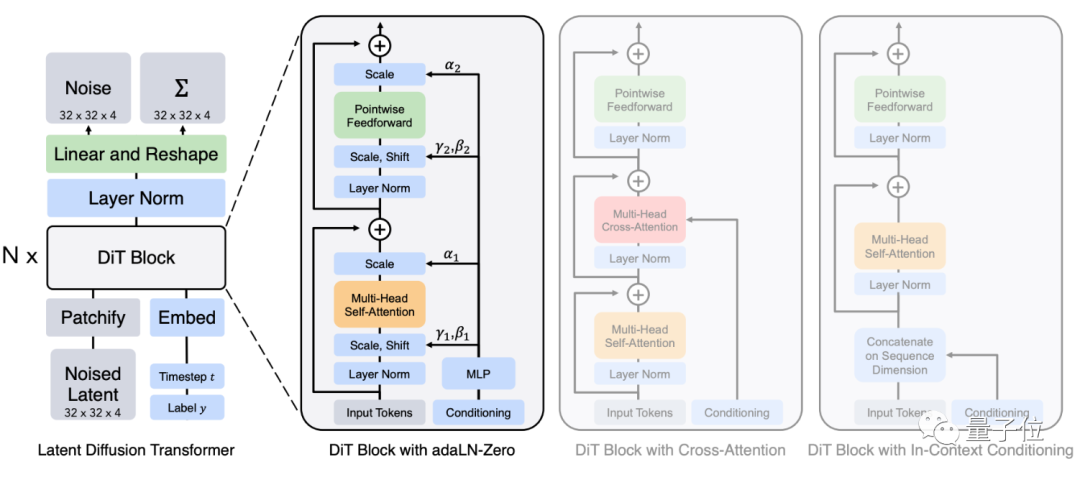
更右边的两个灰色框的模块,则是DiT架构的“变体”。主要是探讨在条件输入下,不同的架构是否能对信息进行更好的处理,包括交叉注意力等。
最终结果表明,还是层归一化(Layer Normalization)更好用,这里最终选用了Adaptive Layer Normalization(自适应层归一化)的方法。
对于这篇论文研究的目的,作者表示希望探讨扩散模型中不同架构选择的重要性,以及也是给将来生成模型的评估做一个评判标准。
先说结果——作者认为,U-Net的归纳偏置(inductive bias),对于扩散模型性能提升不是必须的。
与之相反,他们能“轻松地”(readily)被Transformer的标准架构取代。

有网友发现,DALL·E和DALL·E2似乎都有用到Transformer。
这篇论文和它们的差异究竟在哪里?
事实上,DALL·E虽然是Transformer,但并非扩散模型,本质是基于VQVAE架构实现的;
至于DALL·E2和Stable Diffusion,虽然都分别将Transformer用在了CLIP和文本编码器上,但关键的图像生成用的还是U-Net。
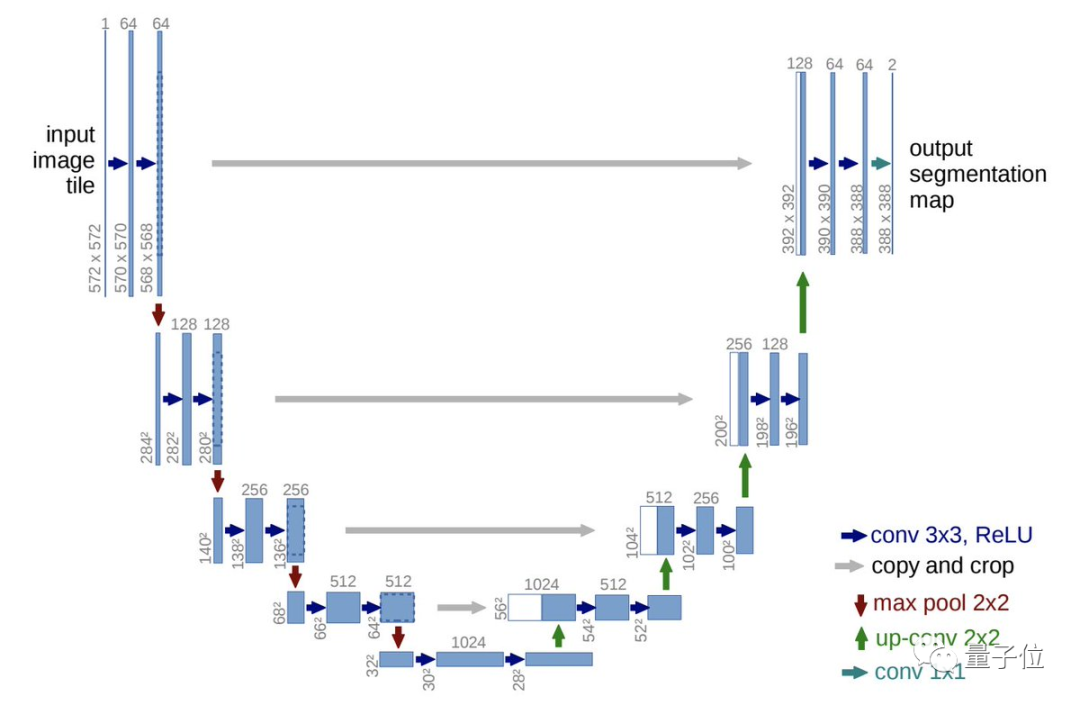
△经典U-Net架构
不过,DiT还不是一个文本生成图像模型——目前只能基于训练标签生成对应的新图像。
虽然生成的图片还带着股“ImageNet风”,不过英伟达AI科学家Jim Fan认为,将它改造成想要的风格和加上文本生成功能,都不是难点。
如果将标签输入调整成其他向量、乃至于文本嵌入,就能很快地将DiT改造成一个文生图模型:
Stable-DiT马上就要来了!

所以DiTs在生成效果和运算速率上,相比其他图像生成模型究竟如何?
在ImageNet基准上取得SOTA
为了验证DiTs的最终效果,研究者将DiTs沿“模型大小”和“输入标记数量”两个轴进行了缩放。
具体来说,他们尝试了四种不同模型深度和宽度的配置:DiT-S、DiT-B、DiT-L和DiT-XL,在此基础上又分别训练了3个潜块大小为8、4和2的模型,总共是12个模型。
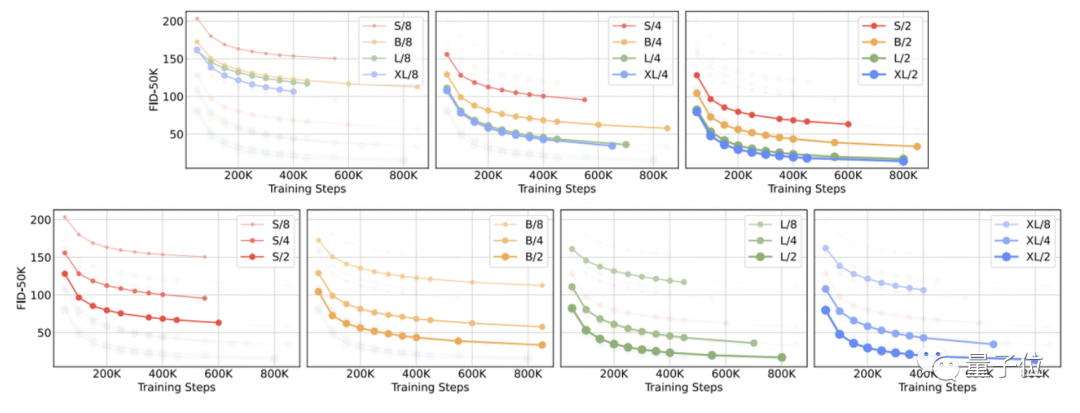
从FID测量结果可以看出,就像其他领域一样,增加模型大小和减少输入标记数量可以大大提高DiT的性能。
FID是计算真实图像和生成图像的特征向量之间距离的一种度量,越小越好。
换句话说,较大的DiTs模型相对于较小的模型是计算效率高的,而且较大的模型比较小的模型需要更少的训练计算来达到给定的FID。
其中,Gflop最高的模型是DiT-XL/2,它使用最大的XL配置,patch大小为2,当训练时间足够长时,DiT-XL/2就是里面的最佳模型。
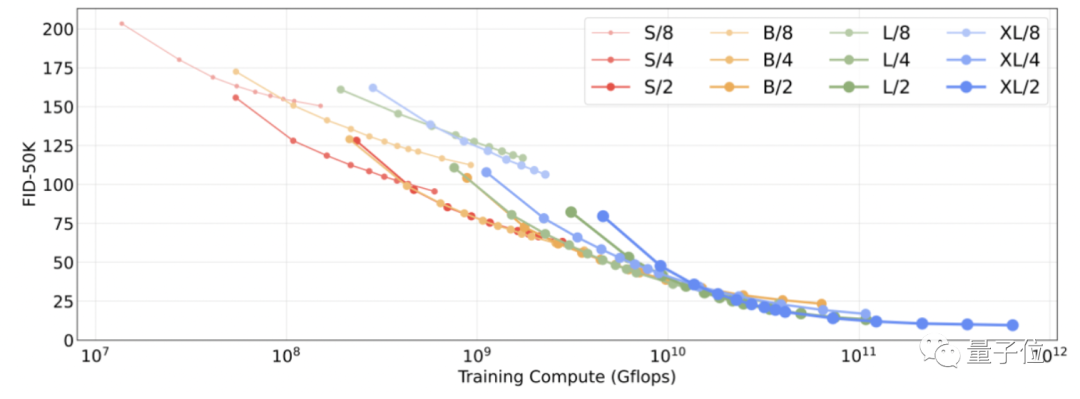
于是在接下来,研究人员就专注于DiT-XL/2,他们在ImageNet上训练了两个版本的DiT-XL/2,分辨率分别为256×256和512×512,步骤分别为7M和3M。
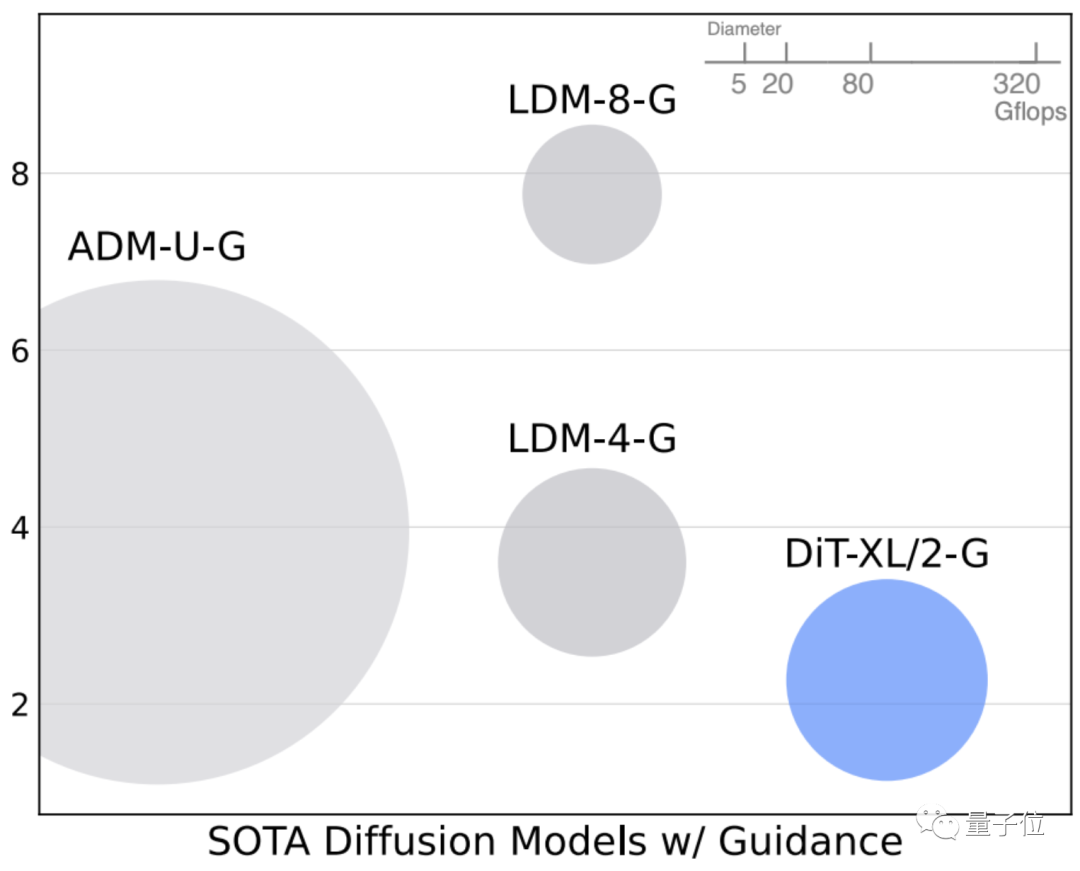
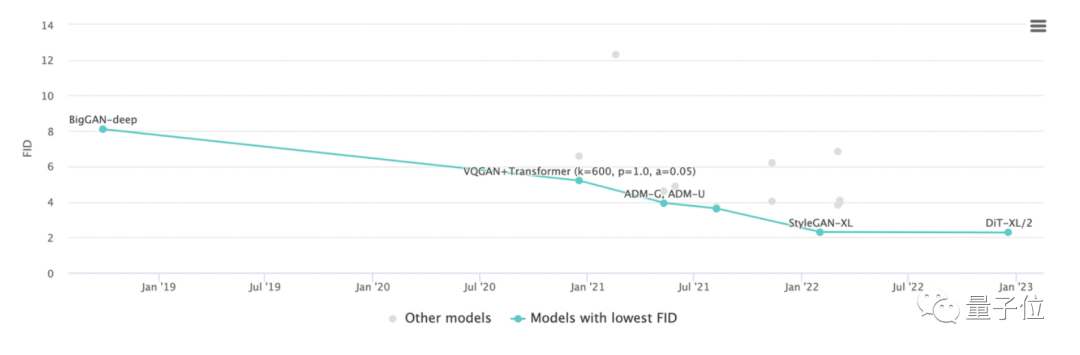
当使用无分类器指导时,DiT-XL/2比之前的扩散模型数据都要更好,取得SOTA效果:
在256×256分辨率下,DiT-XL/2将之前由LDM实现的最佳FID-50K从3.60降至了2.27。
并且与基线相比,DiTs模型本身的计算效率也很高:
DiT-XL/2的计算效率为119 Gflops,相比而言LDM-4是103 Gflops,ADM-U则是742 Gflops。
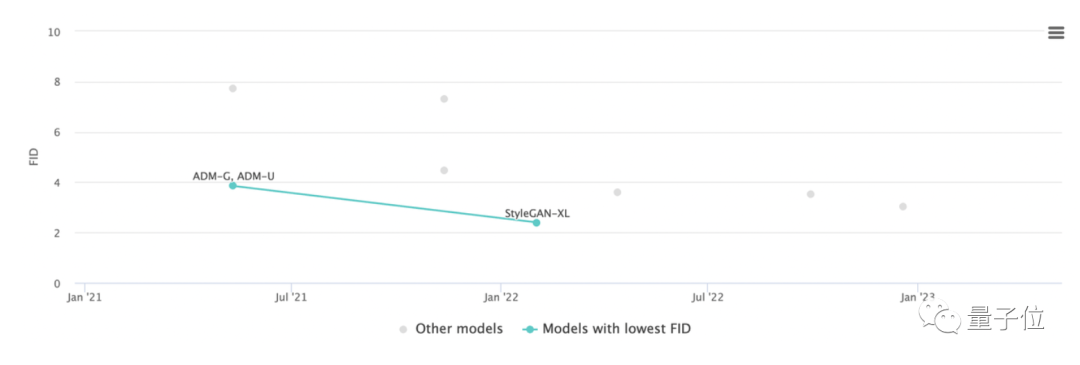
同样,在512×512分辨率下,DiT-XL/2也将ADM-U之前获得的最佳FID 3.85降至了3.04。
不过此时ADM-U的计算效率是2813 Gflops,而XL/2只有525 Gflops。
研究作者
本篇论文作者为UC伯克利的William Peebles和纽约大学的谢赛宁。

William Peebles,目前是UC伯克利的四年级博士生,本科毕业于麻省理工学院。研究方向是深度学习和人工智能,重点是深度生成模型。

之前曾在Meta、Adobe、英伟达实习过,这篇论文就是在Meta实习期间完成。
谢赛宁,纽约大学计算机科学系助理教授,之前曾是Meta FAIR研究员,本科就读于上海交通大学ACM班,博士毕业于UC圣迭戈分校。
谢赛宁读博士时曾在FAIR实习,期间与何恺明合作完成ResNeXt,是该论文的一作,之前何恺明一作论文MAE他也有参与。

当然,对于这次Transformer的表现,也有研究者们表示“U-Net不服”。
例如三星AI Lab科学家Alexia Jolicoeur-Martineau就表示:
U-Net仍然充满生机,我相信只需要经过细小调整,有人能将它做得比Transformer更好。
看来,图像生成领域很快又要掀起新的“较量风暴”了。