谷歌的一份名为《我们没有护城河,OpenAI也没有》的内部文件疑似被泄露,
今天早上,外媒SemiAnalysis公布了这份重磅炸弹泄露文件。
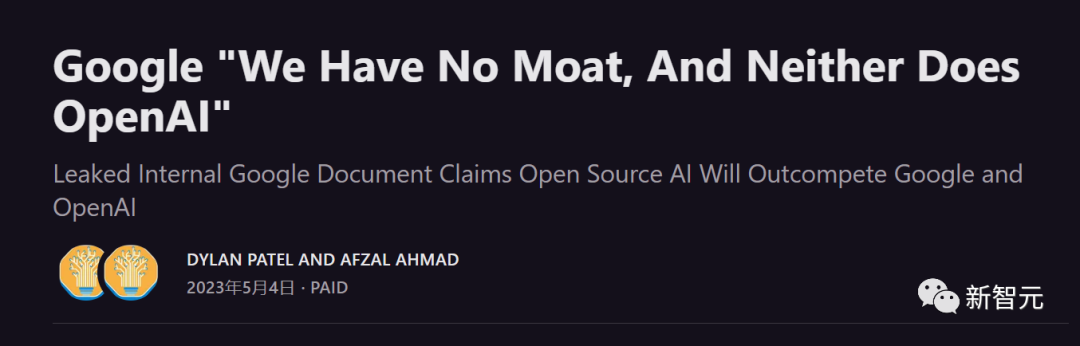
据悉,这份文件是一名匿名人士在Discord服务器上分享出来的,文件来自谷歌内部的一名研究员,真实性已被确认。
SemiAnalysis特别强调,这份文件仅代表谷歌员工的意见,不代表整个公司的意见。
内部文件
我们没有护城河,OpenAI也没有
我们一直在严密监视着OpenAI。谁将跨越下一个里程碑?下一步将是什么?
但现在,令人不安的事实就是:我们无法赢得这场军备竞赛,OpenAI也不能。
就在我们两方对战的时候,第三方正在悄悄地吃掉属于我们的好处。
没错,我说的就是开源。说白了,他们已经超越了我们。我们认为的「重大开放问题」如今已经解决,掌握在所有用户手中。几个简单的例子:
手机上的LLMs:在Pixel 6上,以每秒5个token的速度,就能运行基础模型。
可扩展的个人 AI:只要一个晚上,就能在笔记本电脑上微调出一个个性化AI。
负责任的发布:这一点倒是没有「解决」,说「避免」会更贴切。现在网上到处都是充满了各种艺术模型的网站,没有任何限制,开源的大语言模型也不甘其后。
多模态:当前的多模态 ScienceQA SOTA,只用一个小时就能训练出来。
虽然我们的模型在质量上仍然略有优势,但差距正在以惊人的速度缩小。
这些开源模型更快、更可定制、更私密,性能也更强大。
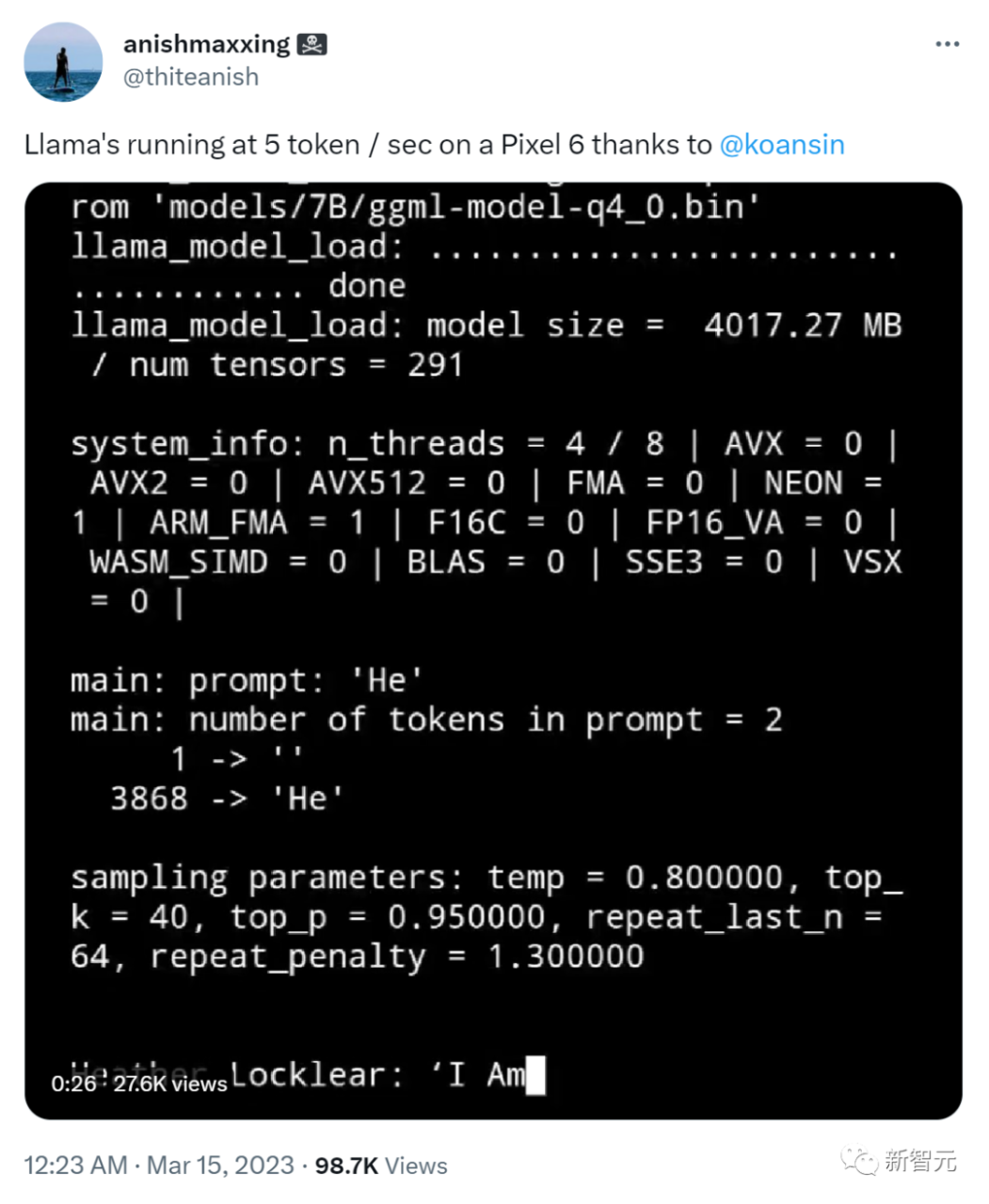
他们只用100美元和13B的参数,就能做到我们用1000万美元和540B的参数下才能做的事。他们在几周内完成,而不是几个月。

Vicuna-13B的质量达到OpenAI ChatGPT和Google Bard的90%*以上
这对我们有着巨大的冲击:
我们没有独家秘密武器了。最大的希望就是,学习其他人正在做的事,与他们合作。我们应该优先考虑允许第三方集成。
当这些免费的、不受限的开源平替具有完全相当的质量,用户不会再为受限的模型付费了。我们应该考虑下,我们真正的增值在哪里。
巨型模型正在减慢我们的速度。从长远来看,最好的模型是那些可以快速迭代的模型。既然我们知道在参数少于200亿时模型会有怎样的可能,我们就应该更关注小模型。
https://lmsys.org/blog/2023-03-30-vicuna/
发生了什么
3月初,随着Meta的LLaMA被泄露给公众,开源社区得到了第一个真正性能强大的基础模型。它没有指令或对话调整,也没有RLHF。
尽管如此,开源社区立刻明白:他们得到的东西有多么重要。
随后,大量创新的开源平替模型不断地涌现出来。每隔几天,就出现一个大进展。
才短短一个月,就有了指令调整、量化、质量改进、人工评估、多模态、RLHF这么多功能的变体,许多还是建立在彼此的基础上的。
最重要的是,他们已经解决了规模的问题,现在任何一个人,都可以参与其中。
如今,许多全新的想法都来自普通人。训练和实验的门槛已经大大降低,从前需要一个大型研究机构合力工作,现在,只需要一台功能强大的笔记本,一个人在一晚上就能搞定。
我们本可以预见到这一切
这对任何人来说,都不算什么惊喜。图像生成领域的复兴之后,紧接着就是开源LLM的复兴。
许多人说,这就是大语言模型的“Stable Diffusion”时刻。

在这两个领域,让公众能够以低成本参与,都是通过低秩适应(LoRA)来实现的。它让微调机制的成本大大降低,
还实现了模型规模的重大突破。(比如图像合成的Latent Diffusion,LLM的Chinchilla)
在获得足够高质量的模型后,世界各地的个人和机构都开始了一系列对模型的创新和迭代。而这些创新,也迅速超越了大科技公司。
在图像生成领域,这些贡献至关重要,使Stable Diffusion走上了与Dall-E完全不同的道路。
Stable Diffuision的开源,导致了产品集成、市场、用户界面的创新,而在Dall-E身上,这些却没有发生。
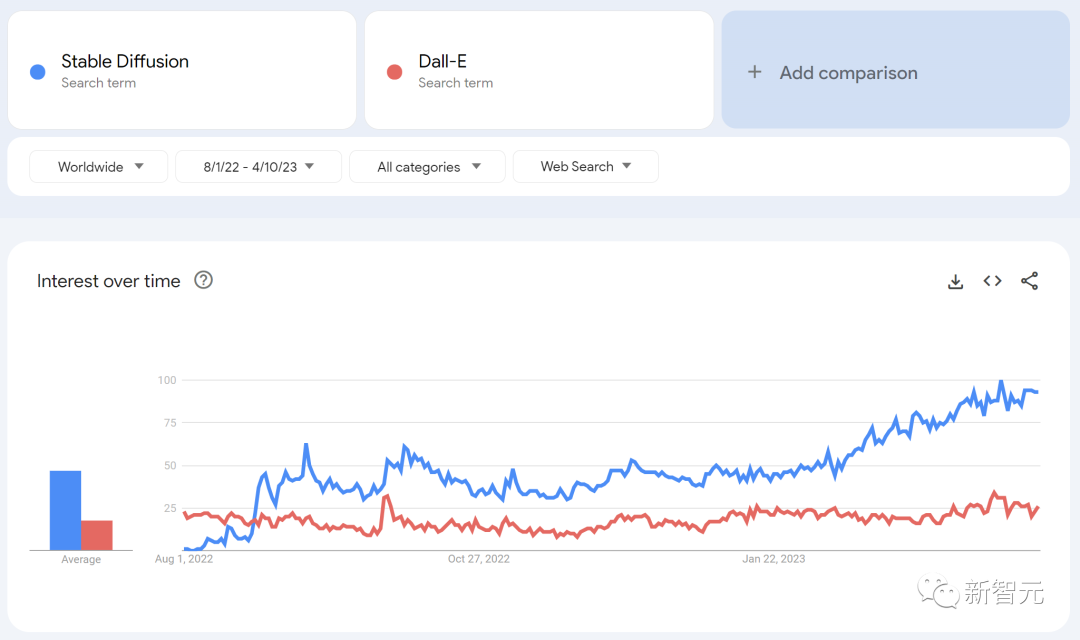
这样做的后果是显而易见的,Stable Diffusion迅速占据了主流,与之相比,OpenAI的解决方案已经变得无关紧要了。
同样的事情是否会发生在LLM领域?目前还未知,但这两件事,有太多相似之处。
我们错过了什么?
开源社区最近取得成功的很多创新,直接解决了我们还未解决的很多难题。
更多地关注他们的工作,可以帮我们避免重新造轮子。
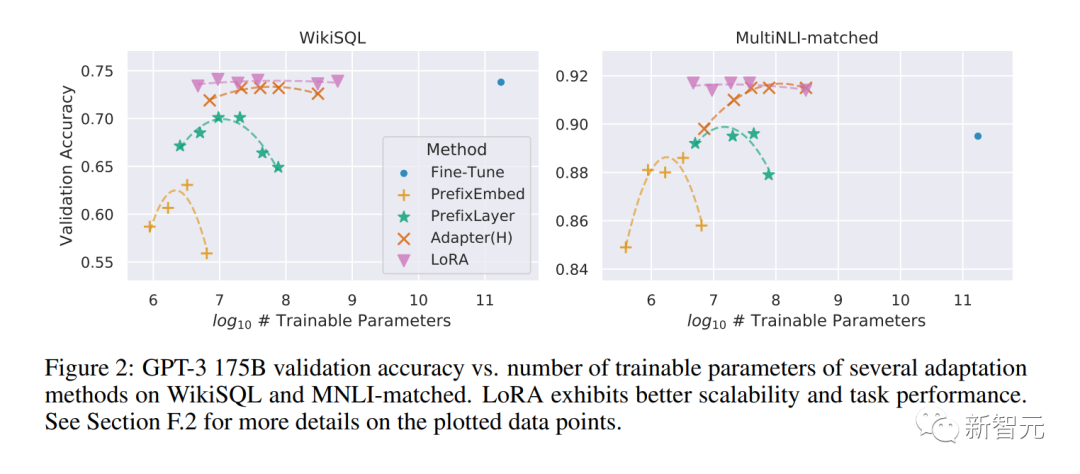
LoRA 是一种非常强大的技术,我们可能应该对它更加关注。

论文地址:
https://arxiv.org/pdf/2106.09685.pdf
LoRA 通过将模型更新表示为低秩分解来工作,这将更新矩阵的大小减少了数千倍以上。
这就让模型微调的时间和成本都大大降低。
如果在几个小时内,就能在消费级硬件上微调出一个个性化的语言模型,这件事的意义就太重大了。尤其是,它还可以实时整合许多最新的、多样化的知识。
但这项技术在谷歌内部并未得到充分重视,尽管它直接影响了我们最寄予厚望的项目。
从头开始重新训练模型,是一条艰难的道路
LoRA 如此有效的部分原因在于,与其他形式的微调一样,它是可堆叠的。
可以应用指令调整改进模型,这样在其他贡献者添加对话、推理或工具时,就可以直接使用。
虽然单独的微调是低秩的,但它们的总和不需要,因此模型的全秩更新就可以随着时间的推移而累积。
这意味着,只要有新的、更好的数据集和任务出现,模型就可以以低廉的成本保持最新状态,无需支付完整运行的成本。
相比之下,从头开始训练巨型模型不仅会失去预训练的过程,还会失去在顶部进行的任何迭代改进。
在开源世界中,这些改进很快就会占据主导地位,这使得全面重新训练模型的成本极其昂贵。
我们应该考虑,每个新的应用或想法是否真的需要一个全新的模型?
如果我们真的有重大的架构改进,以至于无法直接重新使用模型权重,那么我们应该去投资更积极的蒸馏形式,来尽可能多地保留上一代模型的功能。
如果我们能够在小模型上快速迭代,那么从长远来看,大模型并不是强到无所不能
LoRA(大型语言模型的低秩适应)是微软提出的一种新颖技术,旨在解决微调大型语言模型的问题。
它的更新对于最受欢迎的模型大小来说非常便宜(约100美元),这意味着几乎任何有想法的人都可以生成一个,并分发出去。
以后,一天之内训练一个模型都是平平事。
以这样的速度,用不了多久,这些微调的累积效应很快就会弥补起初的模型大小的劣势。

事实上,这些模型的改进速度远远超过了我们使用最大模型所能做的,而且最好的模型与ChatGPT在很大程度上已经无法区分。
专注于研究一些大模型,反而让我们处于不利地位。
要数据质量,不要数据规模
许多项目通过对小型、精选数据集上进行训练来节省时间。这表明数据扩展规律具有一定的灵活性。
这样数据集的存在源于「Data Doesn’t Do What You Think」一文中的思路,它们正迅速成为在谷歌之外进行训练的标准方式。
这些数据集是通过合成方法(比如,从现有模型中筛选出最佳响应)和从其他项目中搜集而构建。谷歌在这两者中都不占主导地位。
幸运的是,这些高质量的数据集是开源的,因此可以免费使用。
与开源直接竞争,是一个失败的命题
AI新进展对谷歌的商业战略有着直接、即时的影响。如果有一个免费的、高质量、且没有使用限制的替代品,谁会为谷歌产品付费?
而且我们不应该指望能够赶上。现代互联网之所以依赖开源,是有原因的。开放源码有一些我们无法复制的显著优势。