在工作场合禁用ChatGPT等生成式人工智能工具,三星最新入列。
再添一员
据多家媒体5月3日报道,三星推出了一项新政策,要求员工不得在工作场所使用OpenAl的ChatGPT和谷歌 Bard等生成式人工智能。据三星称,4月,该公司的一名工程师将内部源代码上传到ChatGPT后,意外泄漏了内部源代码。这让三星担忧其数据将通过人工智能平台最终落入其他用户手中。
目前,三星员工已被禁止在公司设备上使用人工智能工具,包括电脑、平板电脑、手机等,但员工仍可以在个人设备上使用。该公司还强调,若违规并导致公司信息或数据泄漏的话,员工将得到纪律处分,情节严重者将被解雇。

需要指出的是,三星关于生成式人工智能的规定,针对的场景是工作场所,并不限制私人场景的使用。在三星宣布工作场所禁用ChatGPT之前,已经有多家企业巨头对其员工使用ChatGPT提出了要求。
台积电发布内部公告,谨慎使用网络工具如ChatGPT或Bing AI Chat等提醒员工应秉持“不揭露公司信息”、“不分享个人隐私”、“不完全相信生成结果”原则。
日本银行巨头软银,出台了使用交互式人工智能等云服务的指导方针,警告员工使用ChatGPT和其他商业应用,“不要输入公司身份信息或机密数据”。

美国最大的银行摩根大通决定临时限制员工使用近期爆火的新型人工智能聊天机器人ChatGPT。
70多万员工的科技咨询巨头埃森哲,也警告员工不要将客户信息暴露给ChatGPT等聊天工具。
全球电商巨头亚马逊警告员工不要与聊天机器人工具共享机密信息。
日本瑞穗金融集团、三菱日联金融集团和三井住友银行已禁止在公司运营中使用ChatGPT和其他服务。
极限拉扯
随着ChatGPT等生成式人工智能工具应用开始普及,在ChatGPT改变工作方式、改变世界的同时,越来越多的企业和机构意识到隐私保护的紧迫性,制定出合理的数据隐私规范,也迫在眉睫了。
这种隐私数据保护的紧迫性有两个来源,一方面是,人工智能公司需要大量的数据来训练更聪明智能的大模型,访问并索取用户隐私数据,必然造成用户隐私泄露;另一方面是,随着越来越多企业员工将ChatGPT加入工作流,上传的数据中难免会夹带公司机密信息。
业界认为,ChatGPT学习能力极强,还能在与用户对谈的同时,认知错误并学习,越来越多企业禁止员工在与AI对谈揭露公司信息,也算是合理要求。不只是企业,多个欧洲国家已经对ChatGPT提出严格的监管要求,意大利、德国、法国、西班牙等。可见,用户隐私保护已经是必须品,各国已经从法律方面限制人工智能的道德伦理风险了。
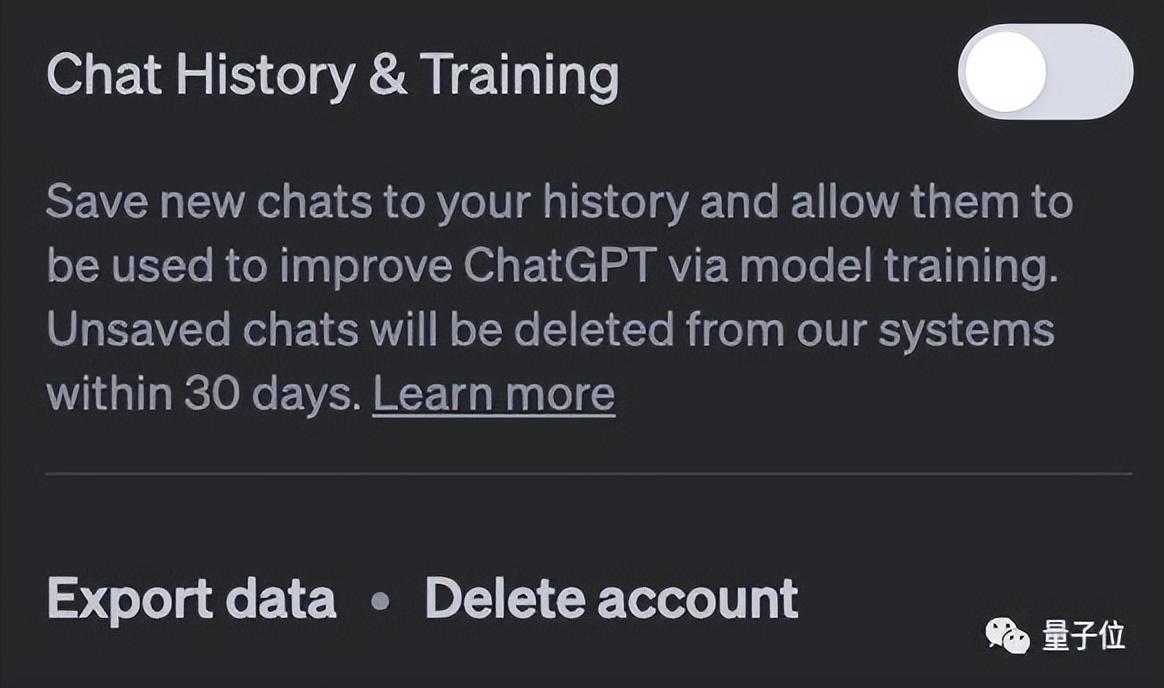
为了应对数据隐私方面的争议,OpenAI最新blog宣布了ChatGPT数据使用的新规则:用户可以通过关闭聊天记录功能,来避免自己的个人数据被官方拿去训练。现在在用户个人管理中,已经出现了一个关闭“Chat history&training”的选项。只要点击取消,历史记录就被禁用了,新的对话也不会再存入聊天记录里。
但新的对话还是会在官方系统里留存30天,OpenAI解释说:只有在监控是否存在数据滥用时才会审查这些数据,30天后将永久删除。同时还上线了一个导出聊天记录的Export功能,方便用户自己保存数据。
有分析认为,用户隐私保护和更好训练模型需要更多数据之间存在极限二选一的困境:用户数据被拿去训练,是ChatGPT对话能力提升的途径之一,数据越多意味着模型能被训练地越精准、聪明;但是这样做必然会侵犯用户的隐私安全。

值得一提的是,这不是OpenAI第一次调整ChatGPT隐私数据使用规则了。3月1日开始,所有调用API接口的用户数据,将不再被用于模型训练,除非用户自愿提供。
不过,有测评人士质疑,ChatGPT功能改进的按钮设置暗藏玄机,关闭聊天记录的按钮设置隐蔽复杂,用户使用的意识和概率都不高,OpenAI保护用户隐私的诚意不够。
从法律上讲,用户隐私必须保护。从技术上讲,大模型训练必需数据。这是两个“刚需”,未来二者还将极限拉扯。