“在 AI 技术生态上,生成式大模型已成为自动驾驶系统进化的关键,基于 Transformer 大模型训练的感知、认知算法,将逐步在车端进行落地部署。”
在最新的毫末 AI DAY 上,毫末智行董事长张凯给出了这一判断,并基于这一判断发布业内首个自动驾驶生成式大模型 DriveGPT,中文名“雪湖·海若”。
自去年年末以来, GPT 的热度一直高涨不下,尤其是 ChatGPT 的大火更是引发全行业关注。此前,GPT 多应用于文本生成、代码生成或是搜索领域,但由于缺乏数据支撑,GPT 在自动驾驶行业这一垂类的应用并不高。
截至目前,业内也仅有毫末一家率先将 GPT 应用到自动驾驶领域,即 DriveGPT 雪湖·海若。
DriveGPT 能为智能驾驶做什么?
GPT 的全称是生成式预训练 Transformer 模型,本质上是在求解下一个词出现的概率。即根据输入的前序文本,模型会输出可能出现的下一个字的几率分布,再从中取样出几率较高的字。如此循环往复,直到完整地写完下文。
据官方介绍,DriveGPT 雪湖·海若的底层模型采用 GPT(Generative Pre-trained Transformer)生成式预训练大模型,与 ChatGPT 使用自然语言进行输入与输出不同,DriveGPT 输入是感知融合后的文本序列,输出是自动驾驶场景文本序列,即将自动驾驶场景 Token 化,形成“Drive Language”。
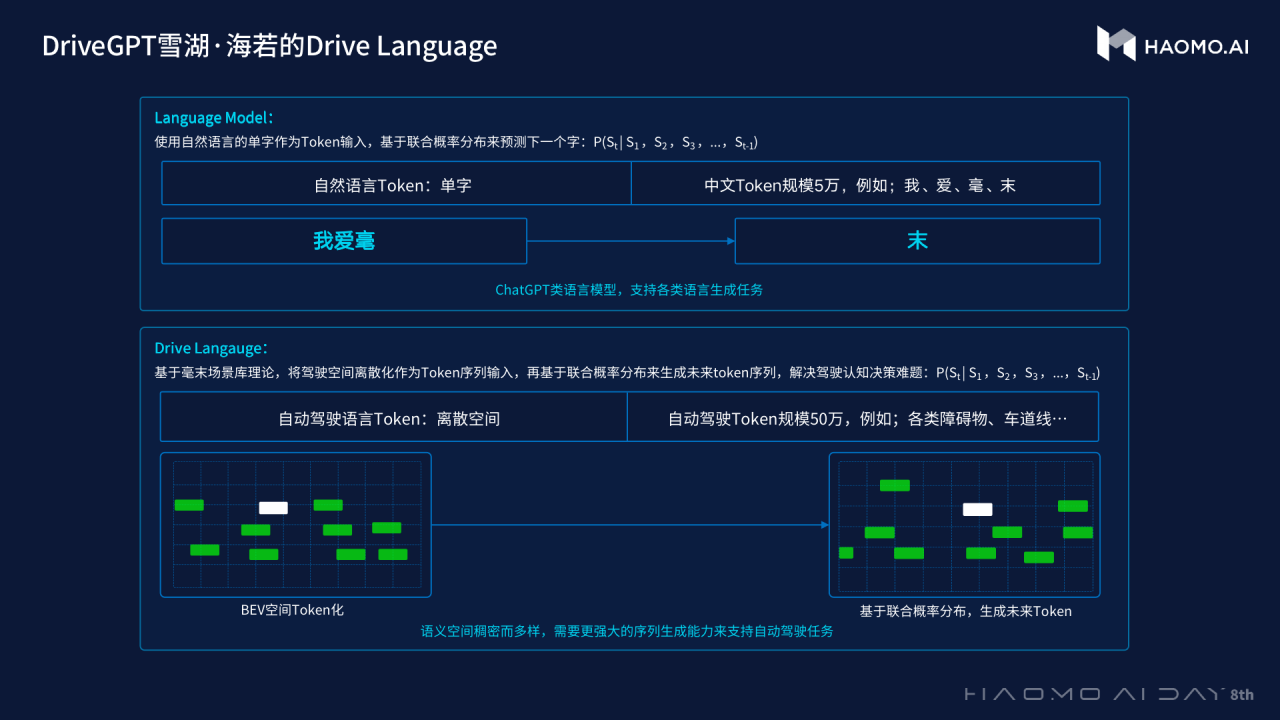
Drive Language 基于毫末的 CSS 场景库理论,将驾驶空间进行离散化处理,每一个 Token 都表征场景的一小部分,相当于许多个可能在未来出现的平行宇宙,最终完成自车的决策规控、障碍物预测以及决策逻辑链的输出等任务。截至目前,毫末从真实驾驶场景库中提取的token序列,规模达到 50 万个。
有了 Drive Language,毫末就可以用人类驾驶的数据对模型进行预训练。
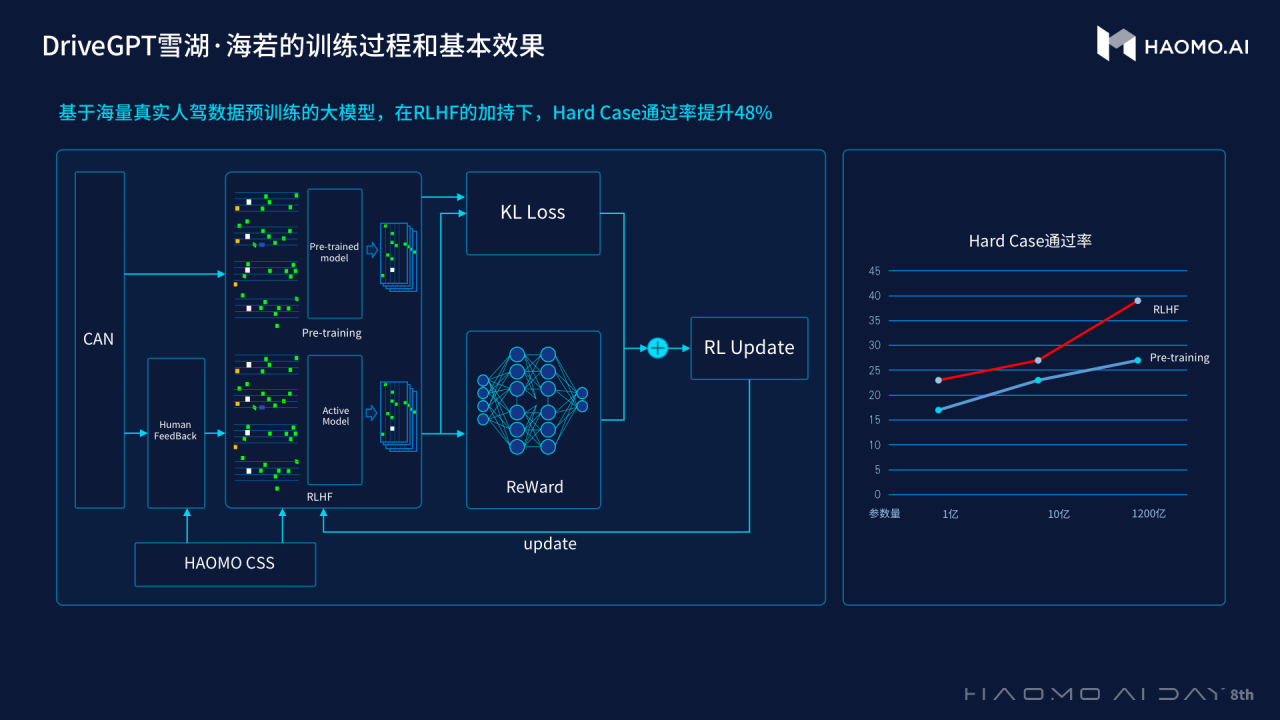
首先,在预训练阶段通过引入量产驾驶数据,训练初始模型,再通过引入驾驶接管 Clips 数据完成反馈模型(Reward Model)的训练,然后再通过强化学习的方式,使用反馈模型去不断优化迭代初始模型,形成对自动驾驶认知决策模型的持续优化。
同时,DriveGPT 雪湖·海若会根据输入端的提示语以及毫末 CSS 自动驾驶场景库的决策样本去训练模型,让模型学习推理关系,从而将完整驾驶策略拆分为自动驾驶场景的动态识别过程,完成可理解、可解释的推理逻辑链生成。
毫末智行 CEO 顾维灏表示,毫末 DriveGPT 雪湖·海若通过引入驾驶数据建立 RLHF(人类反馈强化学习)技术,对自动驾驶认知决策模型进行持续优化。据毫末方面的说法,在 RLHF 的加持下,Hard Case 通过率提升了 48%。
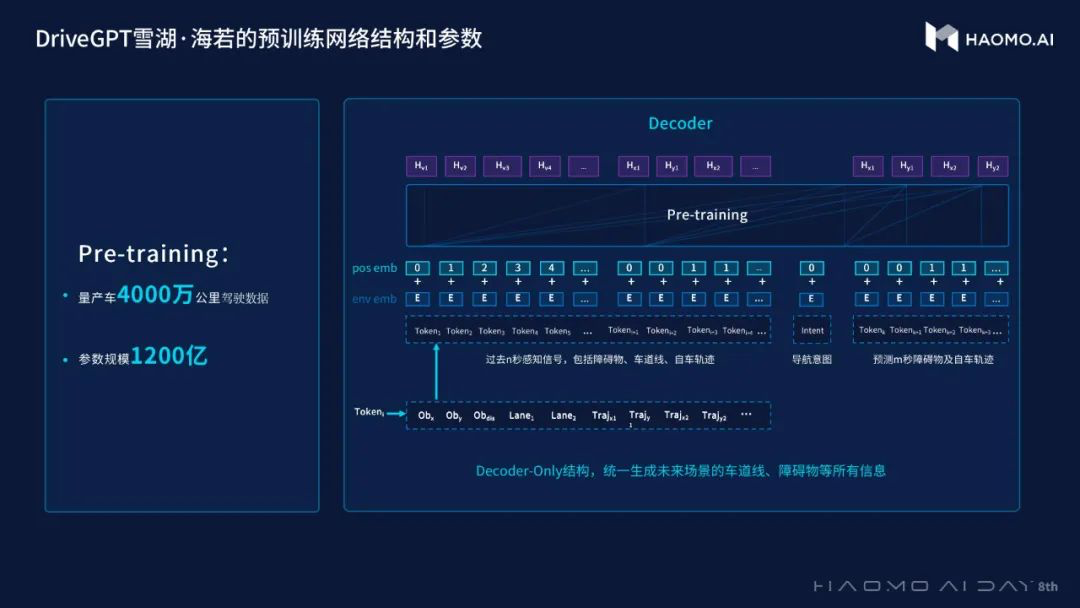
目前,毫末 DriveGPT 雪湖·海若实现了模型架构与参数规模的升级,参数规模达 1200 亿,预训练阶段引入 4000 万公里量产车驾驶数据,RLHF 阶段引入 5 万段人工精选的困难场景接管 Clips。
毫末方面表示,DriveGPT雪湖·海若现阶段主要用于解决自动驾驶的认知决策问题。“在感知到了周围的世界之后,怎么样把车开得更安全,把车开得更顺滑,怎么样跟周围的交通参与者互相博弈。”顾维灏说道。
毫末判断,DriveGPT雪湖·海若还将在城市 NOH、智能陪练、驾驶捷径推荐、脱困场景中得到应用,最终目标是要实现端到端自动驾驶
毫末在 AI DAY 上宣布,DriveGPT雪湖·海若将在即将量产上市的新摩卡DHT-PHEV首发。
毫末基于GPT技术的探索,毫末衍生出服务于业界的能力和新的商业模式,即向业界开放DriveGPT的能力,4月11日开放单帧自动标注服务,可降低标注成本,之后还将陆续开放驾驶行为验证、困难场景脱困等功能。
DriveGPT 背后的支持
事实上,DriveGPT 雪湖·海若的训练和落地,离不开算力的支持。
今年 1 月,毫末和火山引擎共同发布了其自建智算中心“毫末雪湖·绿洲 MANA OASIS”。毫末表示,OASIS 的算力高达 67 亿亿次/秒,存储带宽 2T /秒,通信带宽达到 800G /秒。
不过,只有算力还不够,还需要训练和推理框架的支持,由此毫末进行了三方面升级——
一是训练稳定性优化。毫末在大模型训练框架的基础上,与火山引擎共同建立了全套训练保障框架,可以通过集群调度器实时获取服务器异常,将异常节点从训练 Task group 中删除,再结合CheckPoint 功能,利用 VePFS 高性能存储和 RDMA 网络高效分发,以保障 DriveGPT雪湖·海若大模型训练的稳定性。
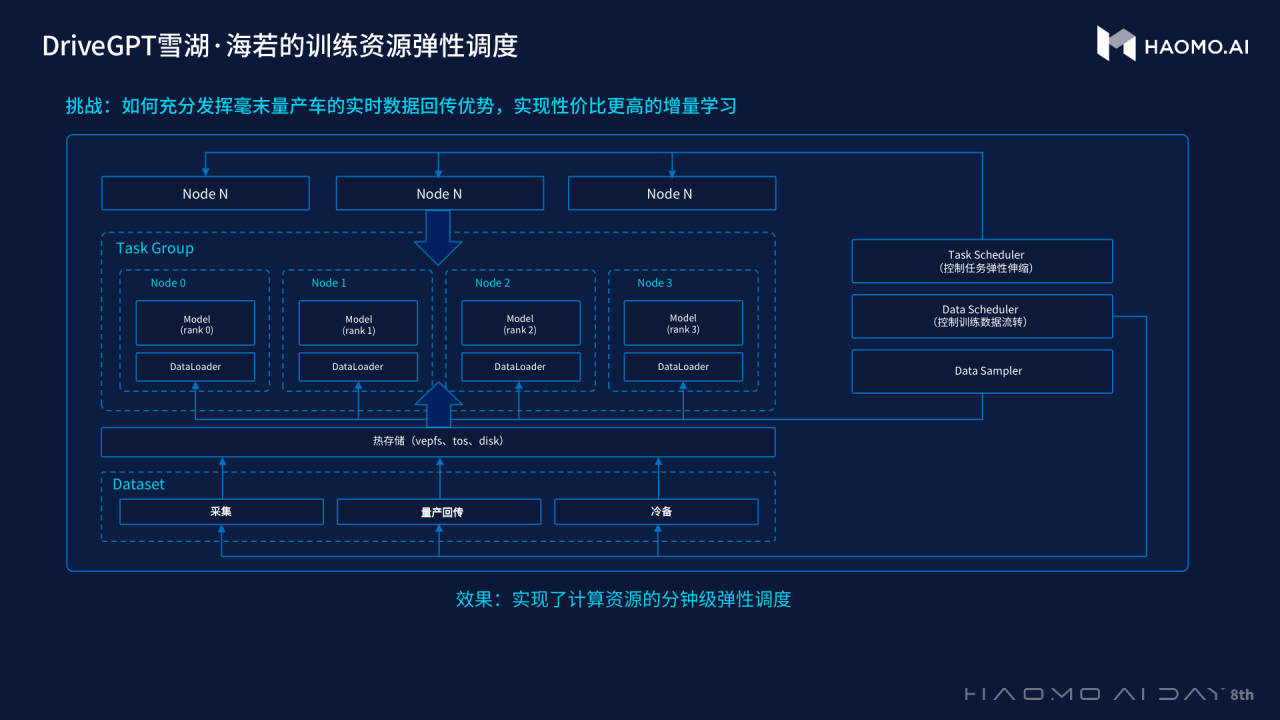
二是弹性调度资源的升级。毫末构建了一个大模型持续学习系统,数据以动态数据流的形式结合增量学习,持续不断地将量产回传和筛选的存量数据,传入认知和感知 Pretrain 大模型。
三是吞吐效率的升级。在 Transformer 的大矩阵计算上,毫末通过对内外循环的数据拆分,尽量保持数据在 SRAM 中提升计算的效率;在传统的训练框架中,通过引入火山引擎提供的 Logo核心算子库实现融合,端到端吞吐提升 84%。
另外,毫末表示,自动驾驶数据智能体系MANA架构已迎来全线升级。截至2023年4月, MANA 学习时长超 56 万小时,相当于人类司机 6.8 万年。
在 MANA 发布迭代一年后,在本次 AI DAY 也迎来升级,具体包括:
首先,MANA 感知和认知相关大模型能力统一整合到 DriveGPT 雪湖·海若中;
其次,MANA计算基础服务针对大模型训练在参数规模、稳定性和效率方面做了专项优化,并集成到 OASIS 中;
第三,增加了使用NeRF技术的数据合成服务,降低 Corner Case 数据的获取成本;
最后,针对多种芯片和多种车型的快速交付难题优化了异构部署工具和车型适配工具。
在视觉感知能力上,毫末对视觉自监督大模型做了一次架构升级,将预测环境的三维结构,速度场和纹理分布融合到一个训练目标里面,强迫模型练好内功,使其能从容应对各种具体任务。目前毫末视觉自监督大模型的数据集超过 400 万 Clips,感知性能提升 20%。