ChatGPT掀起的NLP大语言模型热浪,不仅将各家科技巨头和独角兽们推向风口浪尖,在它背后的神经网络也被纷纷热议。但实际上,除了神经网络之外,知识图谱在AI的发展历程中也被寄予厚望。自然语言处理是如何伴随人工智能各个流派不断发展、沉淀,直至爆发的?本文作者将带来他的思考。
作者 | 王文广
出品 | 新程序员
自ChatGPT推出以来,不仅业内津津乐道并纷纷赞叹自然语言处理(Natural Language Processing, NLP)大模型的魔力,更有探讨通用人工智能(Artificial general intelligence,AGI)的奇点来临。有报道说Google CEO Sundar Pichai发出红色警报(Red code)并促使了谷歌创始人佩奇与布林的回归,以避免受到颠覆性的影响[1][2][3]。同时,根据路透社的报道,ChatGPT发布仅两个月就有1亿用户参与狂欢,成为有史以来用户增长最快的产品[4]。本文以ChatGPT为契机,介绍飞速发展的自然语言处理技术(如图1所示)。
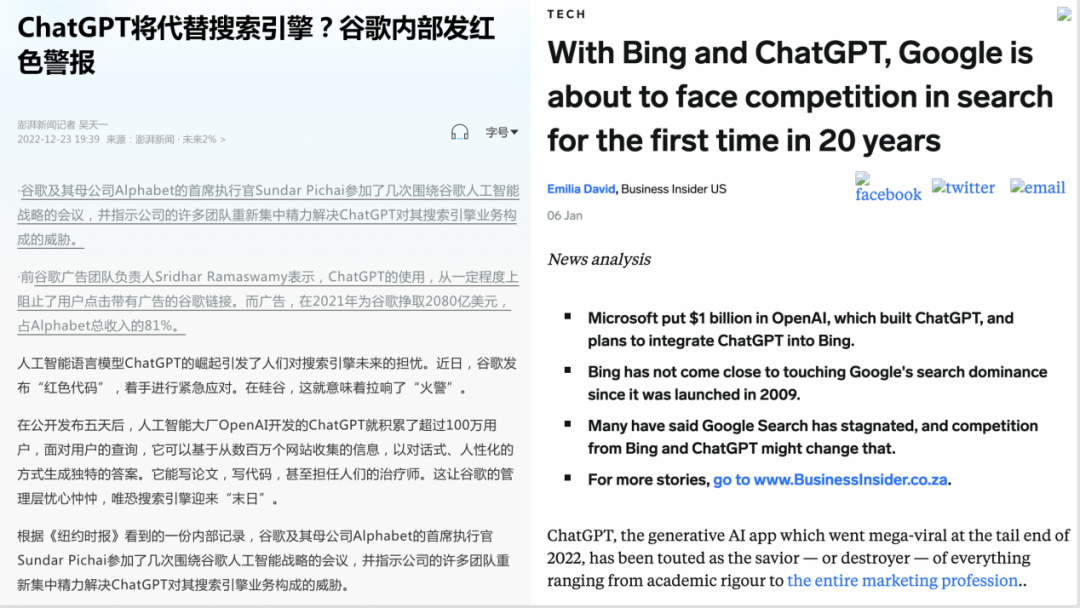
图1 ChatGPT引发 Google“红色警报” [1][2][3]
从机器翻译到ChatGPT:自然语言处理的进化
自然语言处理的历史可以追溯到1949年,恰好与共和国同龄。但是由香农的学生、数学家Warren Weaver发布的有关机器翻译的研讨备忘录被认为是自然语言处理的起点,比1956年达特茅斯会议提出“人工智能(Artificial Intelligence,AI)” 的概念还略早一些。
二十世纪五、六十年代是自然语言处理发展的第一阶段,致力于通过词典、生成语法(图2)和形式语言来研究自然语言,奠定了自然语言处理技术的基础,并使得人们认识到了计算对于语言的重要意义。这个阶段的代表性的成果有1954年自动翻译(俄语到英语)的“Georgetown–IBM实验”,诺姆·乔姆斯基(Noam Chomsky)于1955年提交的博士论文《变换分析(Transformational Analysis)》和1957年出版的著作《句法结构(Syntactic Structures)》等。
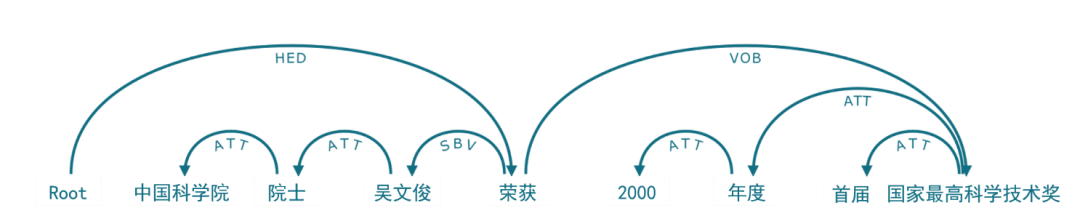
图2 句法分析示例,来自《知识图谱:认知智能理论与实战》图4-5,P149[6]
在二十世纪六、七十年代,对话系统得到了发展,比如SHRDLU、LUNAR和ELIZA(图3)。麻省理工学院的SHRDLU采用句法分析与“启发式理解器(heuristic understander)”相结合的方法来理解语言并做出响应。LUNAR科学自然语言信息系统(Lunar Sciences Natural Language Information System)则试图通过英语对话的方式来帮助科学家们便捷地从阿帕网(ARPA net)获取信息,这倒像是当前爆火的ChatGPT雏形。ELIZA是那时对话系统的集大成者,集成了关键词识别(图4)、最小上下文挖掘、模式匹配和脚本编辑等功能[5]。
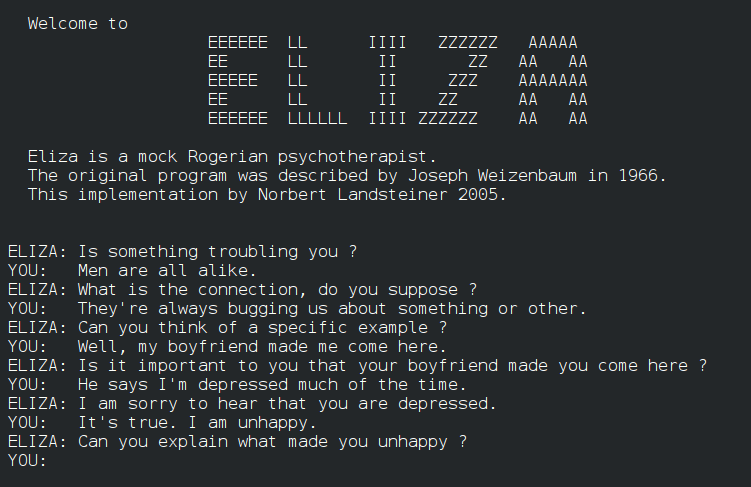
图3 ELIZA对话系统,摘自维基百科ELIZA词条
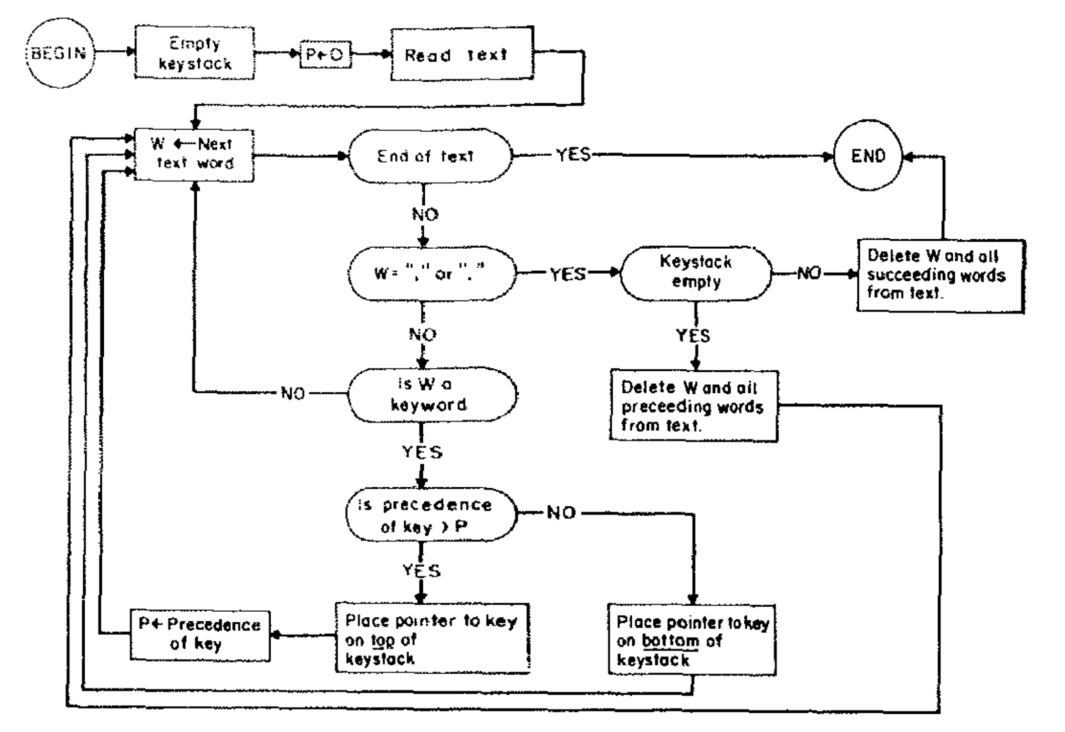
图4 ELIZA系统中关键词挖掘的流程图[5]
随着自然语言处理任务愈加复杂,人们认识到知识的缺乏会导致在复杂任务上难以为继,由此知识驱动人工智能逐渐在二十世纪七、八十年代兴起。语义网络(Semantic Network)和本体(Ontology)是当时研究的热点,其目的是将知识表示成机器能够理解和使用的形式,并最终发展为现在的知识图谱[6]。在这个阶段,WordNet、CYC等大量本体库被构建,基于本体和逻辑的自然语言处理系统是研究热点。
进入二十世纪末二十一世纪初,人们认识到符号方法存在一些问题,比如试图让逻辑与知识覆盖智能的全部方面几乎是不可完成的任务。统计自然语言处理(Statistical NLP)由此兴起并逐渐成为语言建模的核心,其基本理念是将语言处理视为噪声信道信息传输,并通过给出每个消息的观测输出概率来表征传输,从而进行语言建模。相比于符号方法,统计方法灵活性更强,在大量语料支撑下能获得更优的效果。
在统计语言建模中,互信息(Mutual Information)可以用于词汇关系的研究,N元语法(N-Gram)模型是典型的语言模型之一,最大似然准则用于解决语言建模的稀疏问题,浅层神经网络也早早就应用于语言建模,隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Fields ,CRF)(图5)是这个阶段的扛把子。在搜索引擎的推动下,统计自然语言处理在词法分析、机器翻译、序列标注和语音识别等任务中广泛使用。
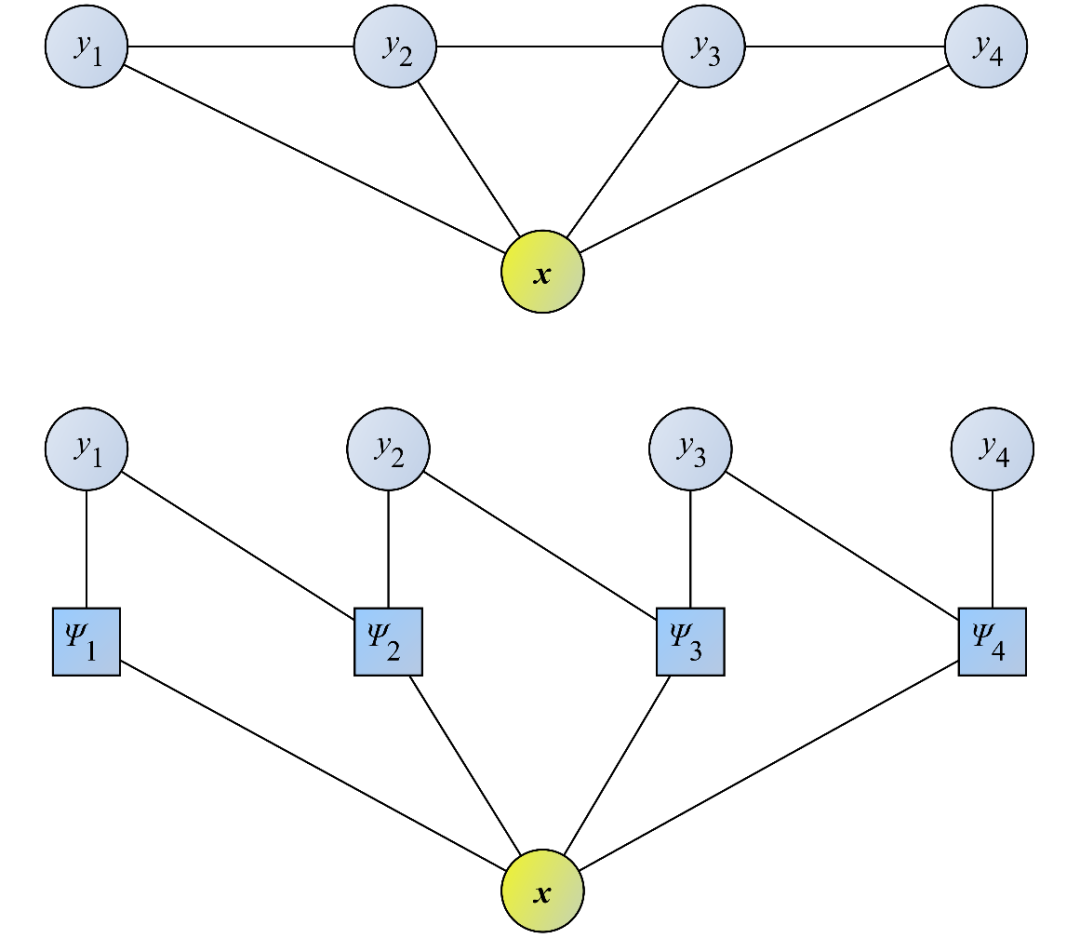
图5 条件随机场,来自《知识图谱:认知智能理论与实战》图3-8,P104[6]
特别地,从这个阶段开始,中文自然语言处理兴起,中国的机构紧紧跟上了人工智能发展的潮流。由于中文分词、词性标注和句法分析等工作与英语等西方语言有着很大的不同,许多针对中文语言处理的方法被深入研究并在推动自然语言处理的发展中发挥着巨大作用。
2006年起,深度学习开始流行,并在人工智能的各个细分领域“大杀四方”,获得了非凡的成就,自然语言处理也开始使用深度学习的方法。随着2013年Word2vec的出现,词汇的稠密向量表示展示出强大的语义表示能力,为自然语言处理广泛使用深度学习方法铺平了道路。从现在来看,Word2vec也是现今预训练大模型的“婴儿”时期。
随后,在循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short-Term Memory,LSTM)、注意力机制、卷积神经网络(Convolutional Neural Network,CNN)、递归神经网络(Recursive Neural Tensor Network)等都被用于构建语言模型,并在句子分类、机器翻译、情感分析、文本摘要、问答系统、实体抽取、关系抽取、事件分析等任务中取得了巨大的成功。
2017年发布的变换器网络(Transformer)[7]极大地改变了人工智能各细分领域所使用的方法,并发展成为今天几乎所有人工智能任务的基本模型。变换器网络基于自注意力(self-attention)机制,支持并行训练模型,为大规模预训练模型打下坚实的基础。自此,自然语言处理开启了一种新的范式,并极大地推进了语言建模和语义理解,成就了今天爆火出圈的 ChatGPT,并让人们能够自信地开始探讨通用人工智能(Artificial General Intelligence,AGI)。