一、ChatGPT对基础科技的启示录
ChatGPT的诞生不仅是人工智能发展的奇异点,还是一个重要的里程碑。因为它(他/她)首次让人类见证了被造物打破启发性(Heuristic)壁垒的时刻。
人工智能(AI)成型于1970年代,是一整套算法和理念的系统性理论。伴随人类对数据处理能力的提高,模拟神经网络并通过训练和推理的机器学习方式逐渐成为了主流。然而,在AI界定当中,除了大家熟知的图灵测试之外,还有一个争论一直困扰着人类。那就是启发性壁垒。所谓启发性壁垒,通俗地讲,就是认为作为人类创造物的AI无法具备人类一样的创作灵感。这是由于AI是基于已知的数据库而训练的,能否像人类一样对未知领域有研究性思维是存疑的焦点。直至5年前,Alpha Zero诞生时,才让人类首次看到了打破启发性壁垒的希望。当时,Alpha Zero掌握了没有教给它的相关概念和知识,在未知领域获得了推理结论,并依靠这些人类棋谱没有的棋路,战胜了人类。如今,ChatGPT之所以能够火爆全球的原因之一就是具备了更广泛的创作性(或者说,打破了启发性壁垒)。上线短短两个月就斩获了1亿月活跃用户,成为史上增长最快的消费级应用。而另一方面,人类对ChatGPT的危机感也恰恰就是来自于它自身的启发性。特别是,ChatGPT可以为用户提供部分人类都难以做到的创作性工作,例如文章撰写、程序编写等等。
综上所述,ChatGPT的出现不再是传统意义上的计算机智能化助手,而是从根本思维上颠覆了人类社会的未来走向。当我们揭开ChatGPT的面纱,你会发现它(她/他)的开发逻辑是近些年逐步替代了RNN(循环神经网络)和 CNN(卷积神经网络) 的Transformer架构语言模型。相较于RNN,Transformer引入了自我注意力(Self-attention)机制,结合算法优化可以实现并行运算,大量节约训练时间。可以看出,Transformer作为AI算法的进化是计算机软件层面的一个发展。因此,为了支撑这种算法的不断进化,需要一整套通用算力系统,而不是把大量资源投入到执行特定已知算法的专用芯片(ASIC,Application Specific Integrated Circuit)当中。换句话说,要想诞生ChatGPT这样的革命性成果,需要构建的是由高精度GPGPU(通用协处理器)+ CPU(中央处理器)的通用异构计算体系,让各种尝试和各种创新在通用体系上自由生长。而事实上,ChatGPT也正是在这种由高精度GPGPU组成的异构计算体系中诞生的。
在我国,过热的AI应用技术已经迎来了瓶颈,很多AI公司走向了AI专用芯片的道路。这种走向固化硬件的环境只能带来应用层面的发展,而无法带来革命性进步。在旧地图中,找不到新地址;没有通用化的计算沃土,也就没有了基础科技的发展。这也就是为什么《三体》中的“智子”锁死地球的基础科学,而对应用科技相对放任的缘故。因此,我们应该感谢ChatGPT的诞生,它让我们理性地思考AI的发展方向和未来竞争力,让我们不再为计算机视觉等应用层面的AI成就而欢呼。更让我们戒骄戒躁,认识到构建通用型算力的重要性。在过去的几年中,我们已经错失了通用量子计算机的“霸权”奇异点,又在去年相继失去了可控核聚变和生成型人工智能的先机。那么,支撑基础科技奇异点的的高精度GPGPU到底是一种什么样的存在呢?
二、揭开ChatGPT的算力面纱
所谓GPGPU是一种弱化GPU的图形显示能力,而将全部资源投入并行计算的处理器。同时,高精度GPGPU需要复杂的高精度设计,又需要先进工艺制程的加持,是我们国家至今所欠缺的领域。高精度GPGPU同时拥有超高算力、极低能耗、及极强的可编程性。因此,高精度GPGPU不仅可以适配各种AI算法,更能为AI与各行业的融合发展提供沃土。因此,由高精度GPGPU构成的异构计算体系支撑了整个工业、科研、国防和民生十余个领域的数字化智能化发展。从国际巨头英伟达(NVIDIA)的财报当中可以看出,其旗舰GPGPU产品(用于高性能计算和人工智能的新型数据中心)占总收入的50%以上,是支撑英伟达公司高达近3.5万亿人民币市值的最大一块业务,同时也是该公司最强劲增长的业务板块之一。除了得益于近5年来在计算解决方案的深耕,英伟达建立的辐射20余个行业的广泛市场根基就是基于这种可以全精度覆盖(特别是高精度)的GPGPU旗舰产品。反观我国的GPGPU发展,起步较晚,存在高精度壁垒。纵观全国,目前有一家成立于2019年的“北京红山微电子技术有限公司”能够提供与美国英伟达(NVIDIA)和超微(AMD)一样的全精度GPGPU。此外,另有中科海光推出的DCU产品,能够作为并行计算加速芯片覆盖到64位高精度,但其分类并不是GPGPU。2020年之后,我国的投资界兴起了对GPU/GPGPU的投资热潮,有不下十余家的企业大规模融资。然而,根据各家的测试数据和官网信息,这些企业当中的绝大多数(除上述的北京红山微电子技术有限公司之外)尚未打破高精度GPGPU的壁垒。由于精度壁垒和应用能力的不足,造成了国产GPGPU在应用市场受到重挫,很多GPU/GPGPU公司甚至无法实现销售,使得整个投资市场骤然降温。此外,很多国产GPU/GPGPU公司为了短期成型,采购了海外的第三方设计IP,实质上仅做了SoC(System on a Chip)的工作,并没有掌握GPGPU的设计核心。甚至有些公司的GPGPU无法达到32位精度,连支撑ChatGPT的训练都不充分。一时间,中国国产的GPGPU成为了市场的怪谈,越来越多的谣言更加误导了市场。
部分国内外旗舰GPGPU(红框内覆盖全精度)列表
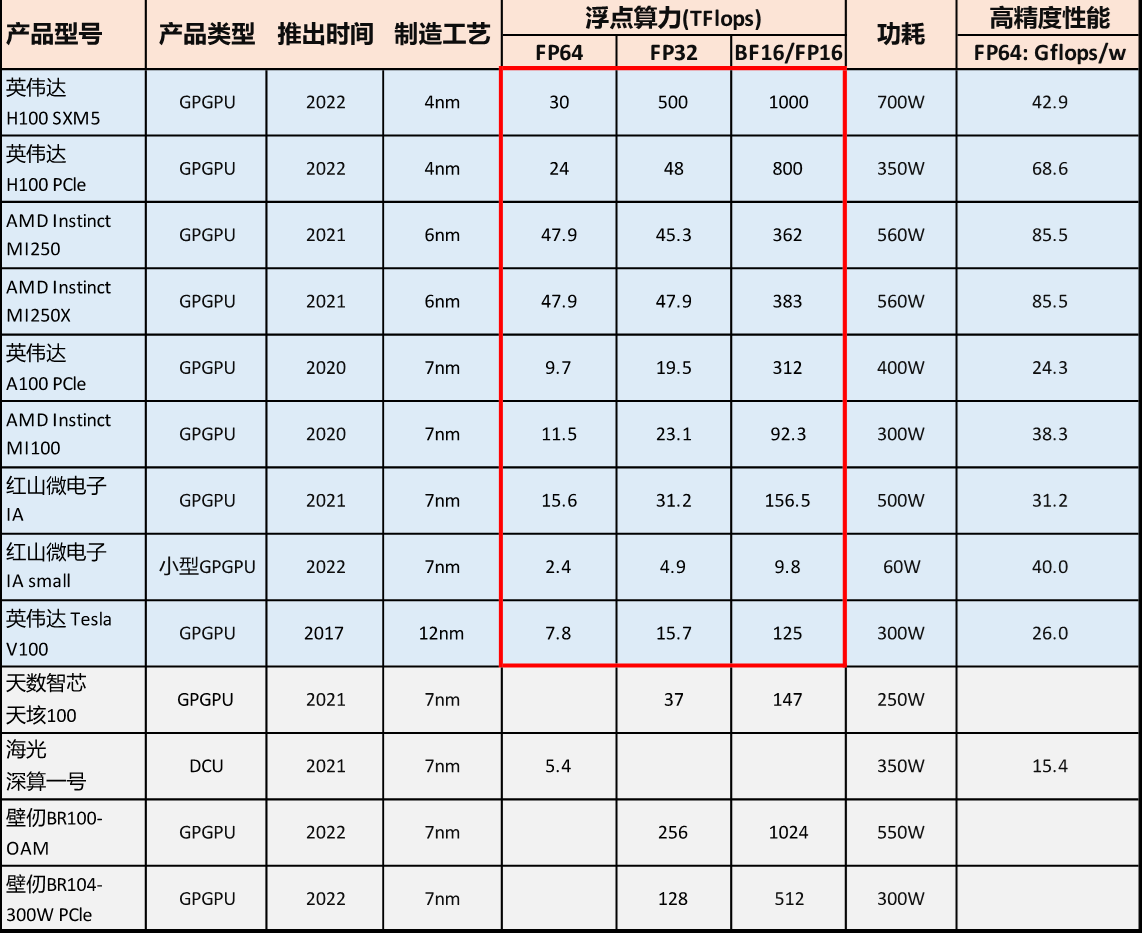
来源:中信证券报告,官网公开信息
根据IDC数据,2021年,GPU/GPGPU服务器以91.9%的份额占我国加速服务器市场的主导地位;NPU、ASIC和FPGA等非GPU加速服务器仅占比8.1%。高精度GPGPU在加速硬件能力上的优势比较明显,在深度学习训练方面最为适用,对美国英伟达的依存度极高。
我国高性能及AI服务器中各类加速芯片占比
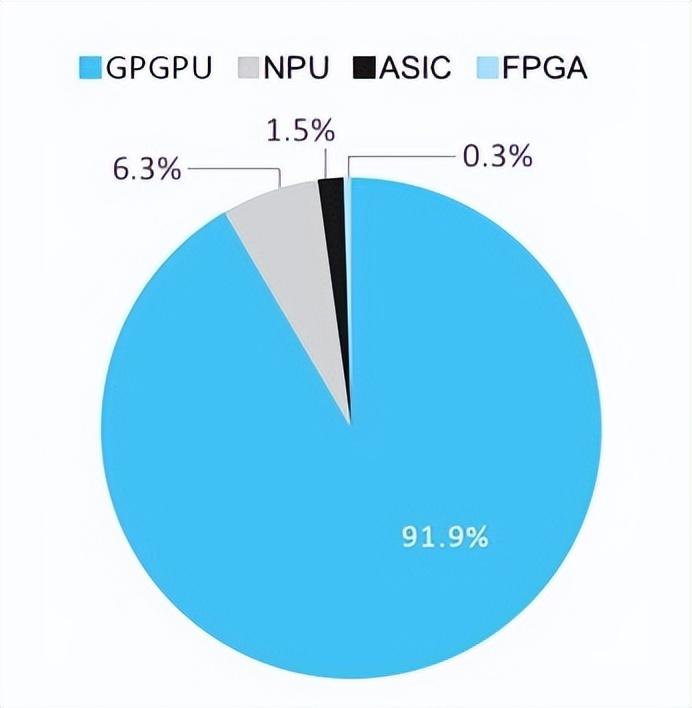
来源:IDC
三、打破关于高精度GPGPU的几大谣言
谣言1:高精度(64位)无用论
目前高精度GPGPU芯片(含FP64/FP32)对我国芯片领域仍然是项“卡脖子”技术,这是因为64位高精度GPGPU设计异常复杂,在同等浮点计算能力的情况下,64位计算精度的设计区域大,逻辑门难度较32位精度设计呈指数级递增。
在AI的训练方面,由于大模型训练成本极高(GPT-3训练成本约为460万美元/次),为提高模型准确性,降低再训练风险,因此对单次大模型的训练精度要求极高,更高的训练精度可以降低代码出错的频率,提升模型训练效率。
因为采用不同位数的浮点数的表达精度不一样,所以造成的计算误差也不一样,对于需要处理的数字范围大而且需要精确计算的科学计算来说,更需要采用高精度GPGPU的双精度浮点计算能力(FP64),可覆盖工业、科研与国防等所有应用领域。
全精度覆盖的市场:AI与HPC应用混合精度计算(FP64/FP32)
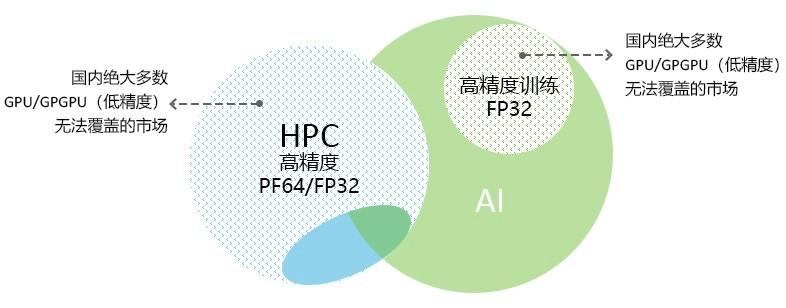
国内大部分GPU/GPGPU能够覆盖的市场
因此,具备全精度覆盖能力的GPGPU(特别是高精度)将辐射人工智能(AI)与高性能计算(HPC)的所有领域,意味着AI的统计推理和高性能计算(HPC)的第一性原理相结合,是两种传统研究范式应用的叠加。这种叠加正是多个万亿级市场的数字化及智能化根基,包括药物设计、新材料、航空航天、自动驾驶、基因工程和新能源领域。
因此,从GPU龙头企业英伟达的旗舰产品白皮书中可以看出,其对64位高精度浮点计算的布局占25%,对64/32位高精度区域的布局占整个芯片的约一半左右,是市场反应在产品上的缩影,更是该公司旗舰产品核心中的核心。
以ChatGPT应用的美国英伟达公司高精度GPGPU举例:
英伟达最新一代高精度GPGPU Hopper架构中的SMP(流处理块)
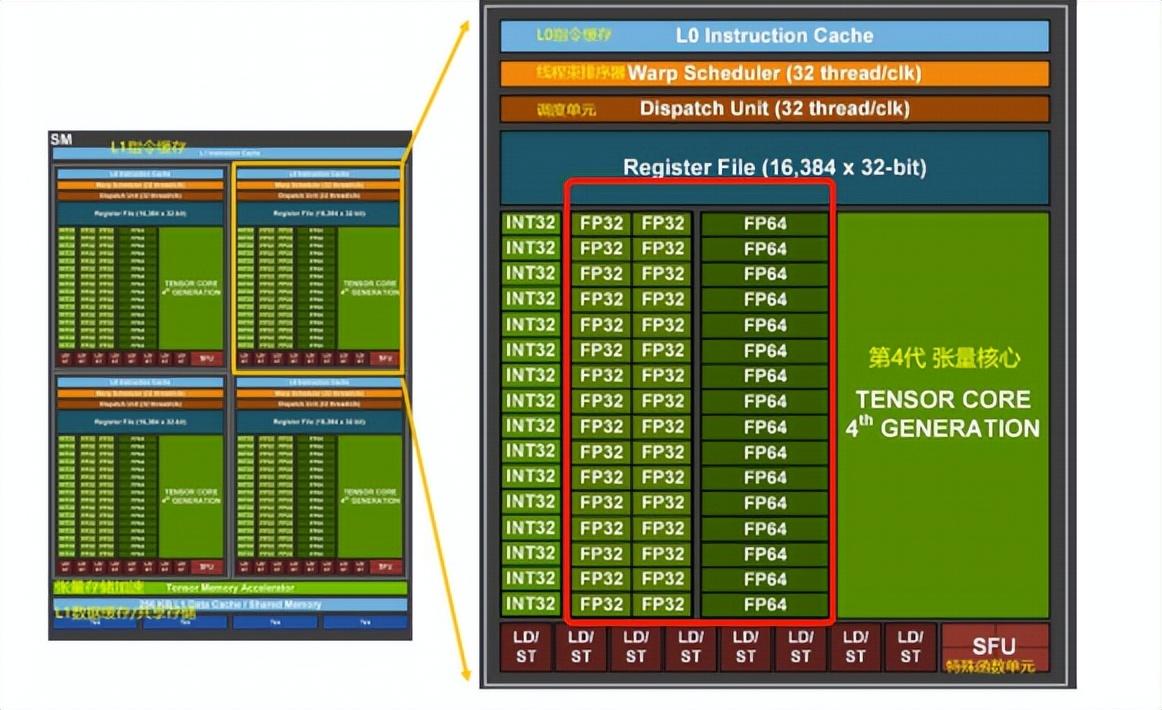
50%芯片面积设计为高精度浮点运算单元(FP64/FP32)
来源:英伟达H100白皮书
谣言2:ChatGPT等AI只需要低精度,甚至是整数精度
人工智能深度学习模型需要处理两大任务,即训练和推理。 训练需要密集的计算得到模型,没有训练,就不可能会有推理。由于国内绝大多数GPU/GPGPU的精度普遍偏低,因此市场上流传了低精度主导AI的错误言论。过分强调低精度覆盖的AI推理而忽视高精度的训练,则严重误导了市场的发展方向。
AI训练的时候因为要保证前后向传播,每次梯度的更新是很微小的,这个时候需要相对较高的精度。一般来说需要Float型,如FP32,32位的浮点型来处理数据,如果用低精度来训练则代码出错的概率较高。推理对精度的要求没有那么高,可以用低精度,如FP16,也可以用8位的整型(INT8)来做推理,研究结果表明没有特别大的精度损失,但是需要综合考虑功耗、速度等其它问题。
谣言3:国产GPU/GPGPU兼容英伟达的CUDA生态
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由 NVIDIA于2007年推出的通用并行计算架构,专为图形处理单元 (GPU) 上的通用计算开发的并行计算平台和编程模型。借助 CUDA,开发者能够利用 GPU 的强大性能显著加速计算应用。由于CUDA易于编程和性能飞跃,加上拥有广泛而丰富的生态系统,CUDA让NVIDIA的GPU生态圈迅速成型。
由于CUDA的闭源特性,以及快速的更新,后来者很难通过指令翻译等方式完美兼容,即使部分兼容也会有较大的性能损失,导致在性价比上持续落后NVIDIA。另一方面,CUDA毕竟是NVIDIA的专属软件栈,包含了许多NVIDIA GPU硬件的专有特性,这部分在其他厂商的芯片上不能得到体现。因此对于国内厂商来说,还是需要构建自主的软硬件生态。
综上所述, ChatGPT使用了约1万颗英伟达高精度GPGPU来训练AI模型。随着参数量和语料库指数级的扩容,ChatGPT类人工智能需要更充足的算力支持其处理数据,同时需要投入更多高性能的算力芯片来处理千亿级别参数量。随着ChatGPT的横空出世,人工智能作为人类创造物首次打破了启发性壁垒。在可预见的未来,通用型人工智能必将深入到各行各业,成为人类社会变革的新动力。为迎接这个时代的来临,我们应在覆盖全行业全智能化的基础上充分布局。因此,发展我国自己的高精度GPGPU,并基于此构建并行计算生态已刻不容缓。