新智元报道
编辑:好困 Aeneas
【新智元导读】这家成立三年的小初创公司,首次利用深度学习语言模型合成出了自然界中不存在的全新蛋白质,引爆蛋白质设计革命。
人工智能的应用,已经极大地加速了蛋白质工程的研究。
最近,加州伯克利的一家初出茅庐的初创公司再次取得了惊人的进步。
科学家们采用类似ChatGPT的蛋白质工程深度学习语言模型——Progen,首次实现了AI预测蛋白质的合成。
这些蛋白质不仅与已知的完全不同,相似度最低的甚至只有31.4%,但和天然蛋白一样有效。
现在,这项工作已经正式发表于Nature子刊。

论文地址:https://www.nature.com/articles/s41587-022-01618-2
这个实验也表明,自然语言处理虽然是为读写语言文本而开发的,但它也可以学习生物学的一些基本原理。
比肩诺奖的技术
对此,研究人员表示,这项新技术可能会变得比定向进化(获得诺贝尔奖的蛋白质设计技术)更加强大。
「它将通过加快开发可用于从治疗剂到降解塑料等几乎所有用途的新蛋白质,为有50年历史的蛋白质工程领域注入活力。」

这家公司名叫Profluent,由前Salesforce AI研究负责人创立,已获得900万美元的启动资金,用于建立一个集成的湿实验室,并招募机器学习科学家和生物学家。
以往,在自然界中挖掘蛋白质,或者调整蛋白质到所需功能,都十分费力。Profulent的目标是,让这个过程变得毫不费力。
他们做到了。

Profluent创始人兼CEO Ali Madani
Madani在采访中表示,Profulent已经设计出了多个家族的蛋白质。这些蛋白质的功能与样本蛋白(exemplar proteins)一样,因此是具有高活性的酶。
这项任务非常困难,是以zero-shot的方式完成的,这意味着并没有进行多轮优化,甚至根本不提供湿实验室的任何数据。
而最终设计出的蛋白质,是通常需要数百年才能进化出来的高活性蛋白质。
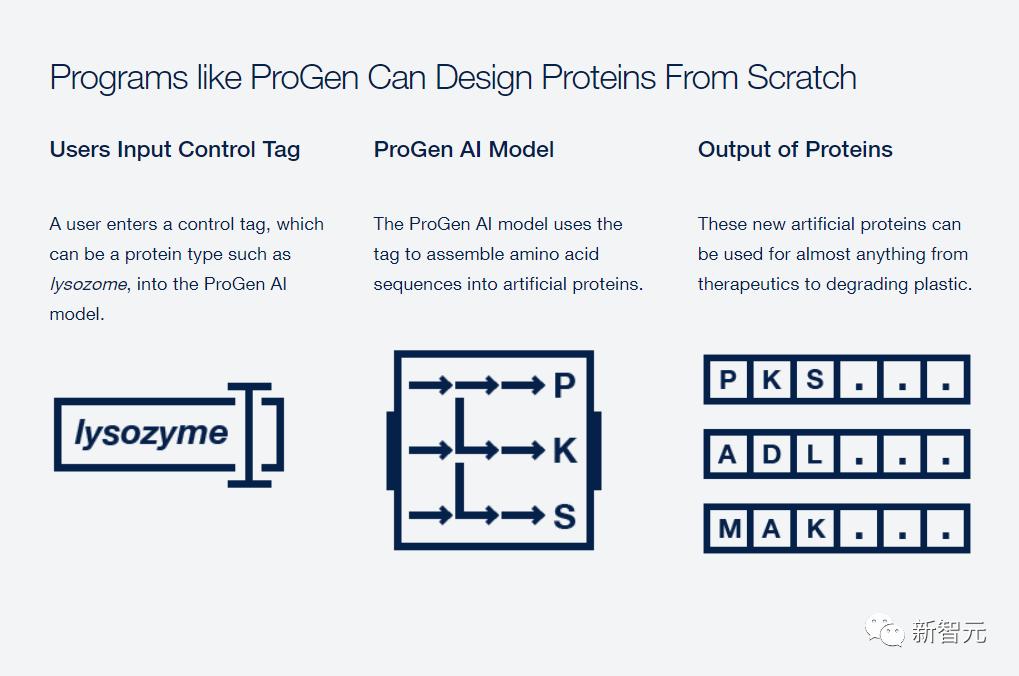
基于语言模型的ProGen
作为深度神经网络的一种,条件语言模型不仅可以生成语义和语法正确且新颖多样的自然语言文本,而且还可以利用输入控制标签来指导风格、主题等等。
类似的,研究人员开发出了今天的主角——ProGen,一个12亿参数的条件蛋白质语言模型。
具体来说,基于Transformer架构的ProGen通过自注意机制来模拟残基的相互作用,并且可以根据输入控制标签生成不同的跨蛋白质家族的人工蛋白质序列。
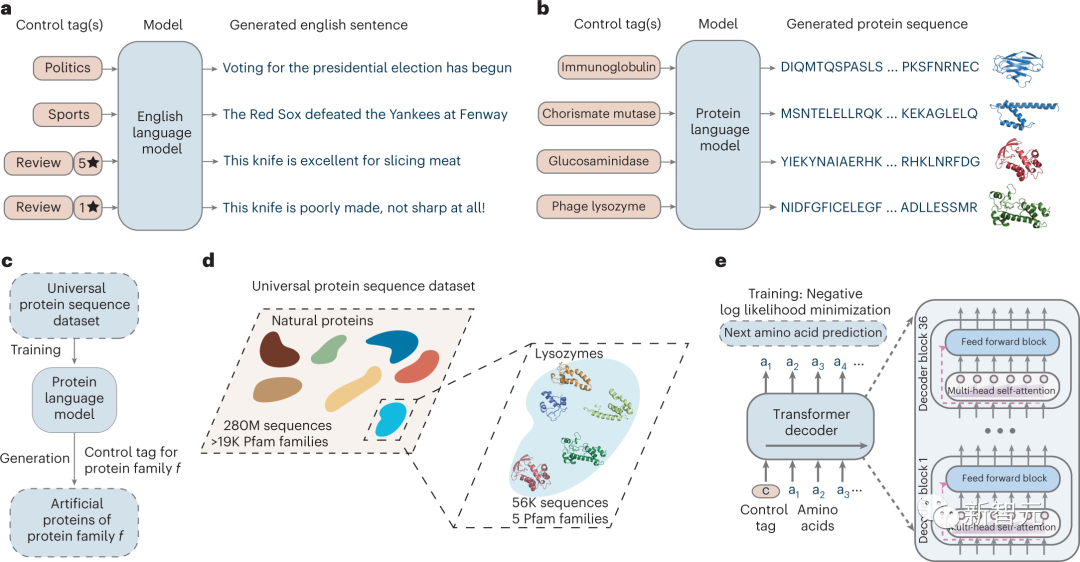
用条件语言模型生成人工蛋白质
为了创建这个模型,研究人员喂了2.8亿种不同蛋白质的氨基酸序列,并让它「消化」了几周的时间。
接着,他们又用五个溶菌酶家族的56,000个序列以及关于这些蛋白质的信息,对模型进行了微调。
Progen的算法与ChatGPT背后的模型GPT3.5类似,它学习到了蛋白质中氨基酸排序的规律,以及它们与蛋白结构和功能的关系。
很快,模型就生成了一百万个序列。
根据与天然蛋白质序列的相似程度,以及氨基酸「语法」和「语义」的自然程度,研究人员选择了100个进行测试。
其中,有66个产生了与消灭蛋清和唾液中细菌的天然蛋白质类似的化学反应。
也就是说,这些由AI生成的新蛋白质也可以杀死细菌。
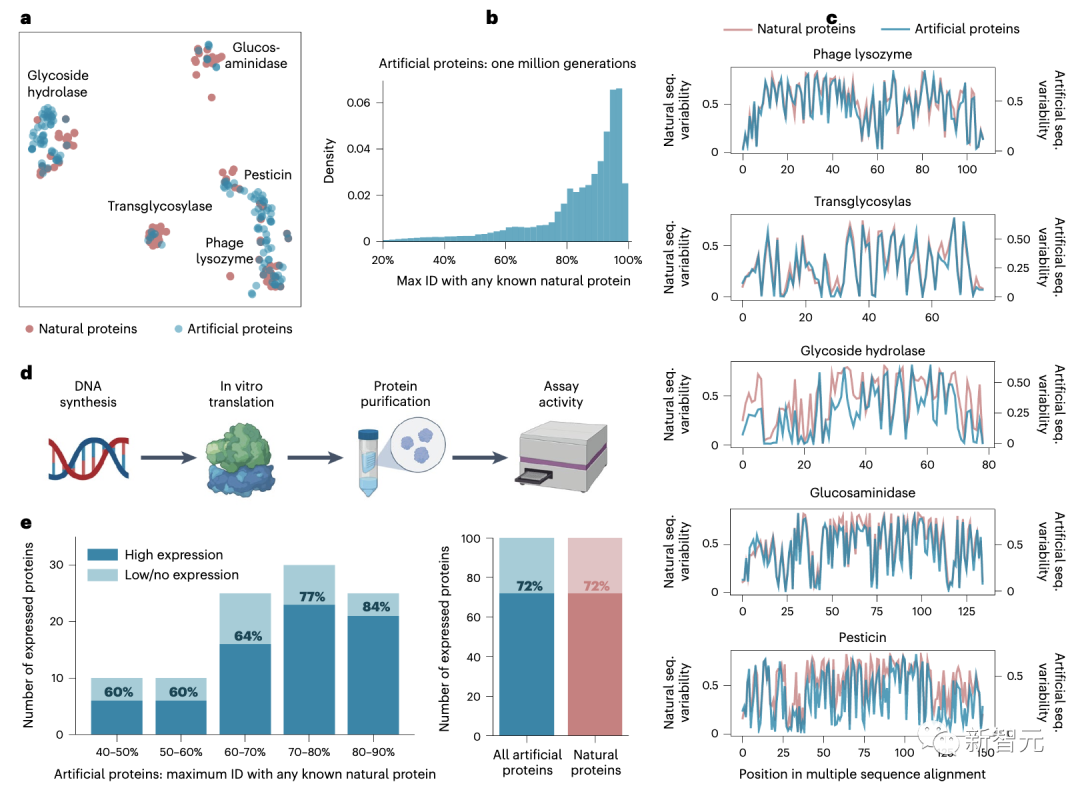
生成的人工蛋白是多样化的,且在实验系统中表达良好
更进一步,研究人员选择了反应最强烈的五种蛋白质,并将它们加入到大肠杆菌的样本中。
其中,有两种人工酶能够分解细菌的细胞壁。
通过与鸡蛋白溶菌酶(HEWL)进行比较可以发现,它们的活性与HEWL相当。
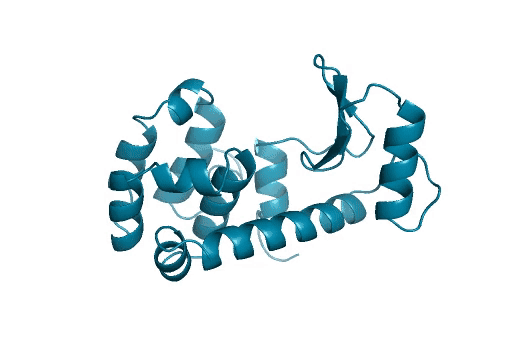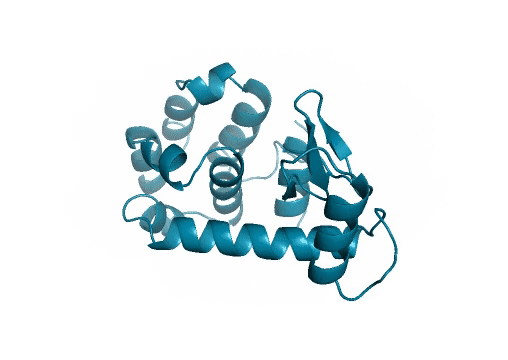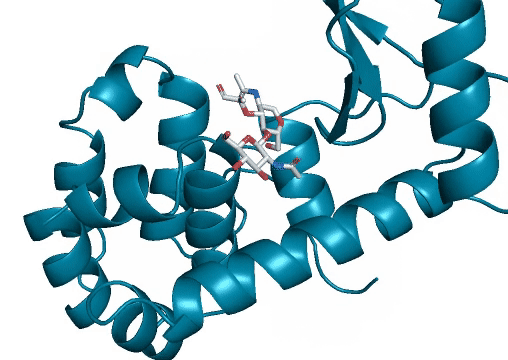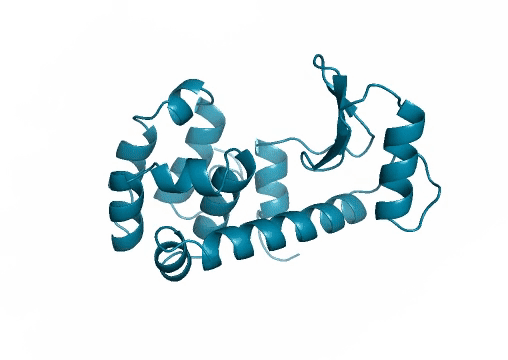
随后,研究人员又用X射线进行了成像。
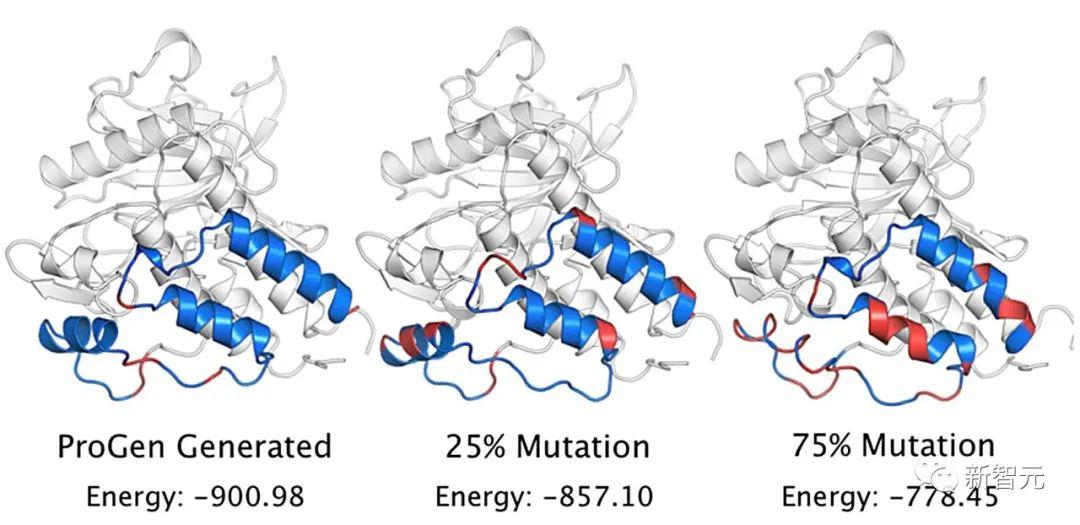
尽管人工酶的氨基酸序列与现有的蛋白质有高达30%的差异,二者之间也只有18%是相同的,但它们的形状却与自然界的蛋白质相差无几,而且功能也可以与之媲美。
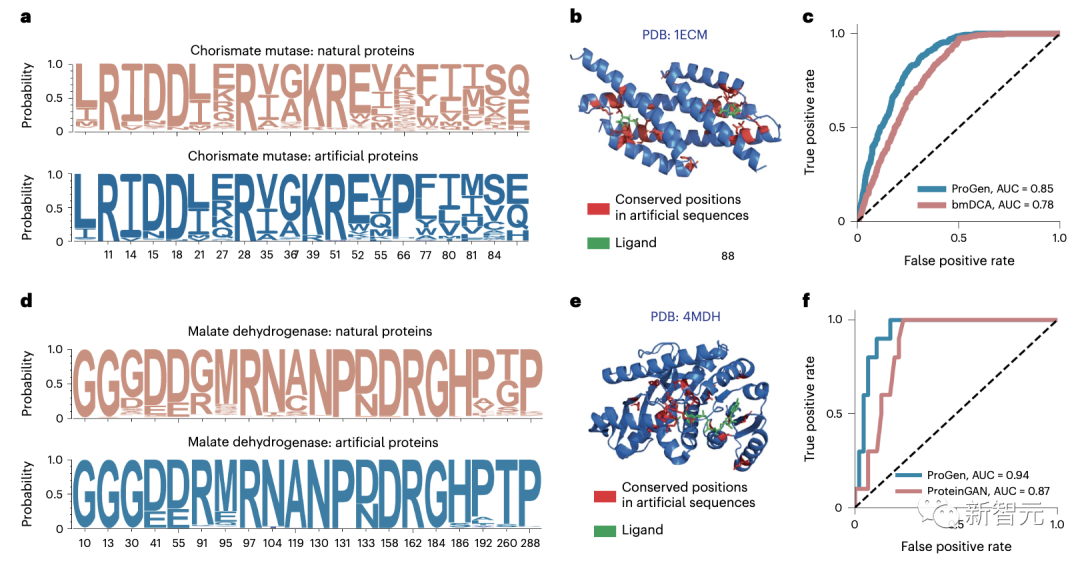
条件语言建模对其他蛋白质系统的适用性
除此之外,对于高度进化的天然蛋白质来说,可能只需一个小小突变就会让它停止工作。
但研究人员在另一轮筛选中发现,在AI生成的酶中,即使只有31.4%的序列与已知蛋白质相同,也能表现出相当的活性以及类似的结构。
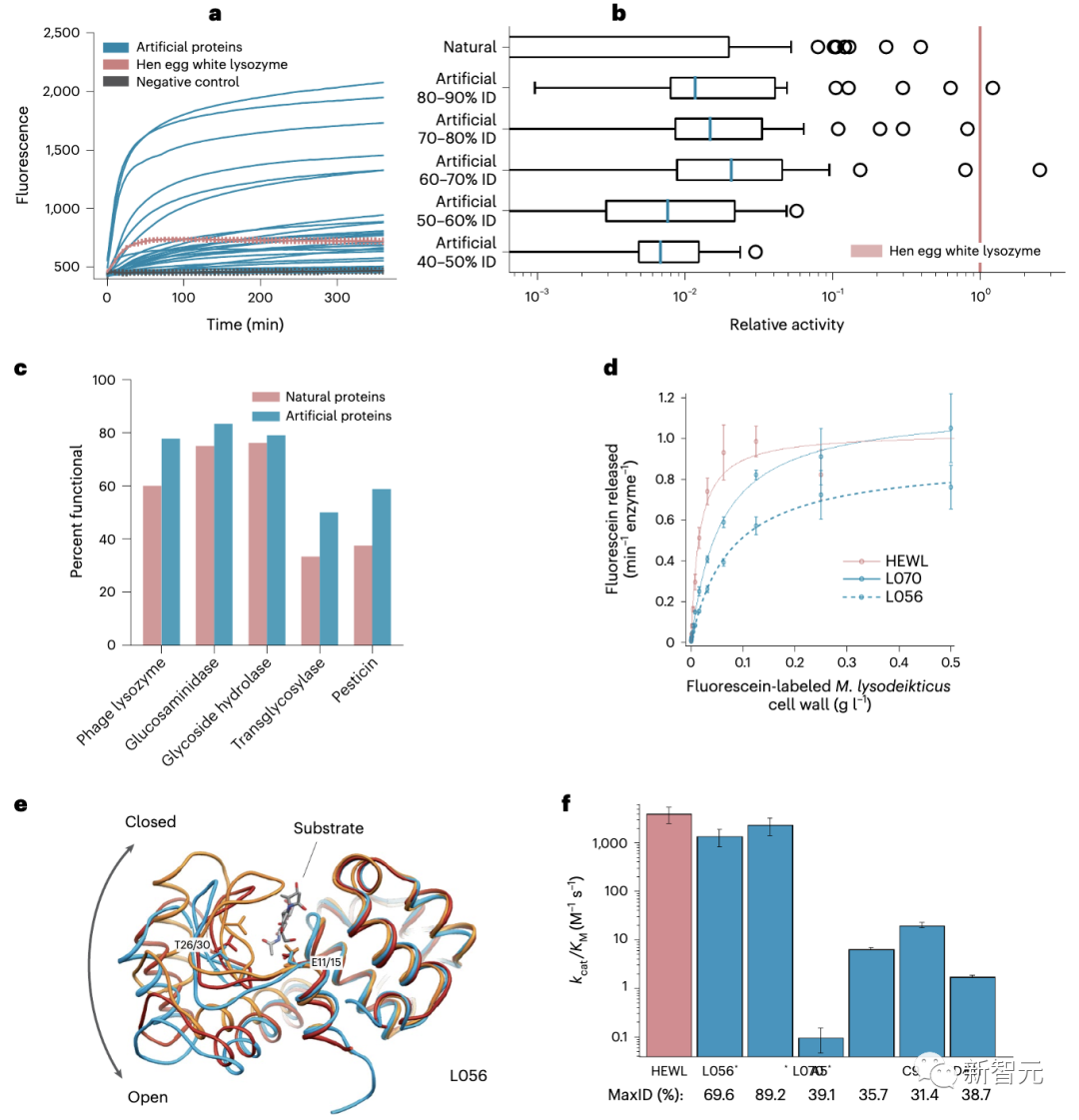
蛋白质设计,进入新时代
可以看到,ProGen的工作方式与ChatGPT很类似。
ChatGPT通过学习海量数据,可以参加MBA和律师考试、撰写大学论文。
而ProGen通过学习氨基酸如何组合成2.8亿个现有蛋白质的语法,学会了如何生成新的蛋白质。
在采访中,Madani表示,「就像ChatGPT学习英语之类的人类语言一样,我们是在学习生物和蛋白质的语言。」
「人工设计蛋白质的性能比受进化过程启发的蛋白质要好得多,」论文作者之一、加州大学旧金山分校药学院生物工程和治疗科学教授James Fraser说。
「语言模型正在学习进化的各个方面,但它与正常的进化过程不同。我们现在有能力调整这些特性的产生,以获得特定效果。比如,让一种酶具有令人难以置信的热稳定性,或嗜好酸性环境,或者不会与其他蛋白质相互作用。」
早在2020年,Salesforce Research就开发了ProGen。它基于的自然语言编程,最初用于生成英语文本。
从之前的工作中,研究者们了解到,人工智能系统可以自学语法和单词的含义,以及其他使写作井井有条的基本规则。
「当你用大量数据训练基于序列的模型时,它们在学习结构和规则上的表现非常强大,」Salesforce Research人工智能研究总监、论文的资深作者Nikhil Naik博士说,「它们会了解哪些词可以同时出现,该怎样组合。」
「现在,我们已经证明了ProGen有能力生成新的蛋白质,并进行了公开发布,所有人都可以在我们的基础上进行研究。」