ChatGPT 自从向世界公开以来一直风靡一时。让我们看一下它演变的一些技术细节。
ChatGPT 是为对话构建的大型语言模型 (LLM) 。它是 InstructGPT 的继任者。这两个模型都是由 OpenAI 构建的。我不会浪费你的时间在另一篇关于它的用途或它如何执行的例子的文章上。
这些模型是聊天机器人(与人类交谈并保持对话的能力),它们是自然语言处理(NLP) 研究的活跃领域。有很多值得注意的尝试(例如,来自 Microsoft 的 Tay)在使用来自 Twitter 的开放数据进行训练后都以惊人的失败告终。
注意:如果您还没有机会查看 ChatGPT,请在此处执行此操作。现在可以免费使用。
跳回:
那么是什么让 ChatGPT 如此特别?!
更好的指导遵循
安全护栏
它是如何做到的?
通过人工标记的数据和巧妙的使用方法。
虽然没有描述 ChatGPT 模型的论文/白皮书,但我们可以从 InstructGPT 获得最接近的技术细节。白皮书 可在此链接中找到。
来自 OpenAI:
我们已经训练了一个名为 ChatGPT 的模型,它以对话方式进行交互。对话格式使 ChatGPT 可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT 是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。
OpenAI 非常清楚地表明 ChatGPT 与 InstructGPT 非常相似,不同之处仅在于训练模型的数据量。
InstructGPT 是 GPT3 的微调版本。GPT3 是受过文本补全训练的 LLM。你给它一些提示;它预测下一个对它有意义的词。但有个问题!由于它只进行文本补全,它并不能真正“理解”您的提示,而且对话更加不连贯。即使在试图用“及时的工程”来哄骗它之后,它也可能会产生错误的、有毒的或反映有害情绪的反应。InstructGPT 修复了这个确切的问题。
将 GPT3 视为感恩节上没有过滤器的种族主义叔叔。他需要其他成年人的“帮助”才能成为 PC 并适合儿童 :D
InstructGPT 通过将模型的目标与人类用户可能喜欢的内容“对齐”来解决这个问题。更真实、更诚实的答案,更少的毒性,等等。
完美,现在让我们进入 InstructGPT 的核心:从人类反馈 (RLHF) 中强化学习。基本上,他们使用一小部分人工标记的数据来构建奖励模型。
为简化起见,请这样看:
通常,强化学习看起来像这样。环境会为每个动作产生奖励。
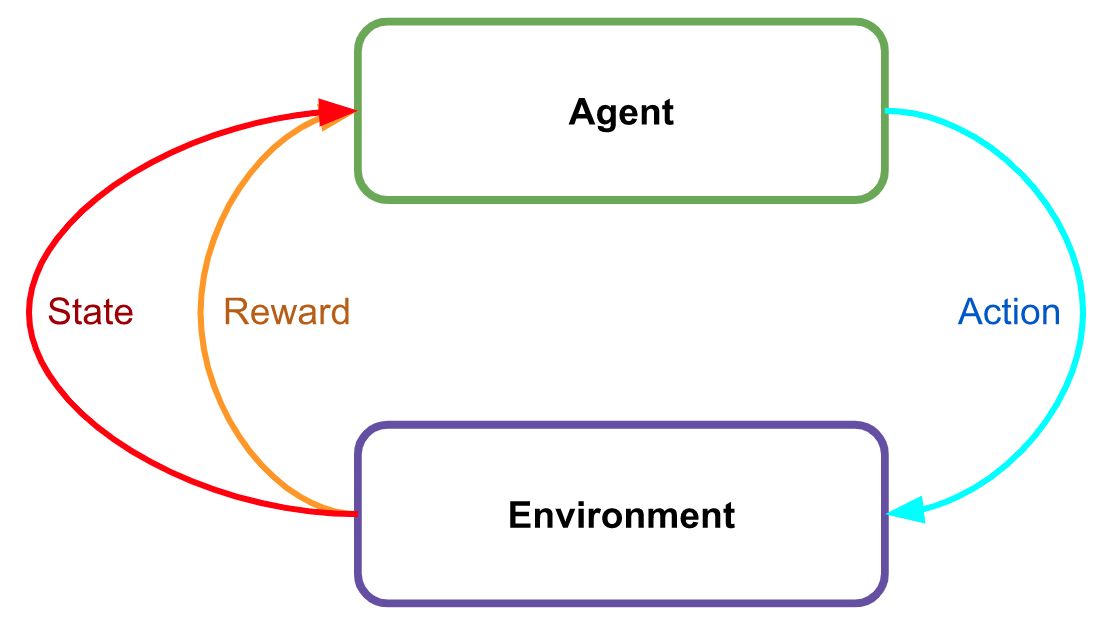
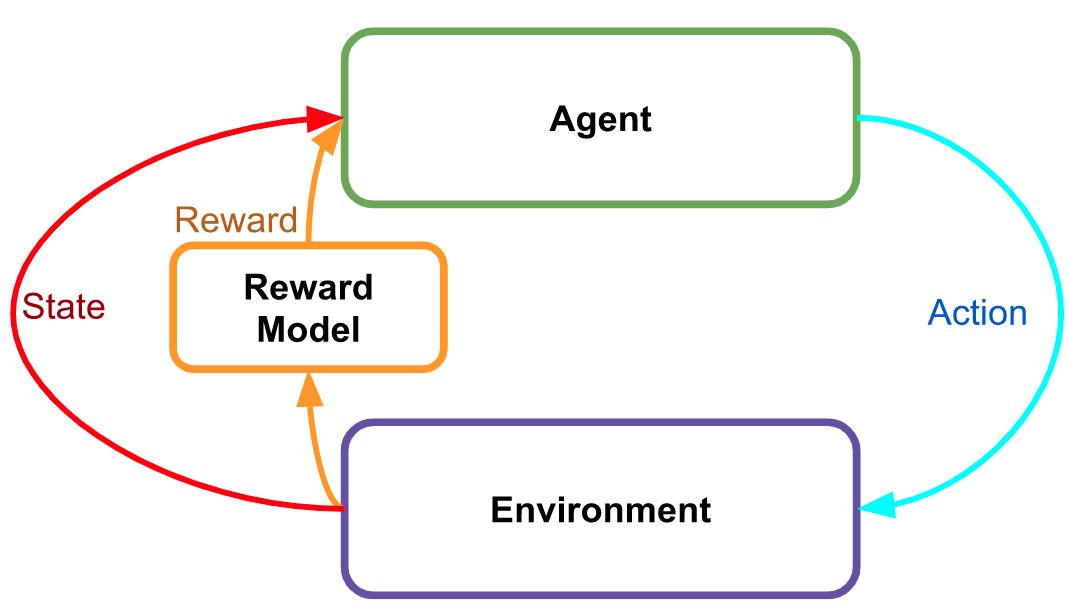
InstructGPT(以及,通过归纳,ChatGPT)使用一个单独的、专门设计的和标记的奖励模型。
图像(来自 OpenAI 的论文)显示了创建此模型的三个步骤。
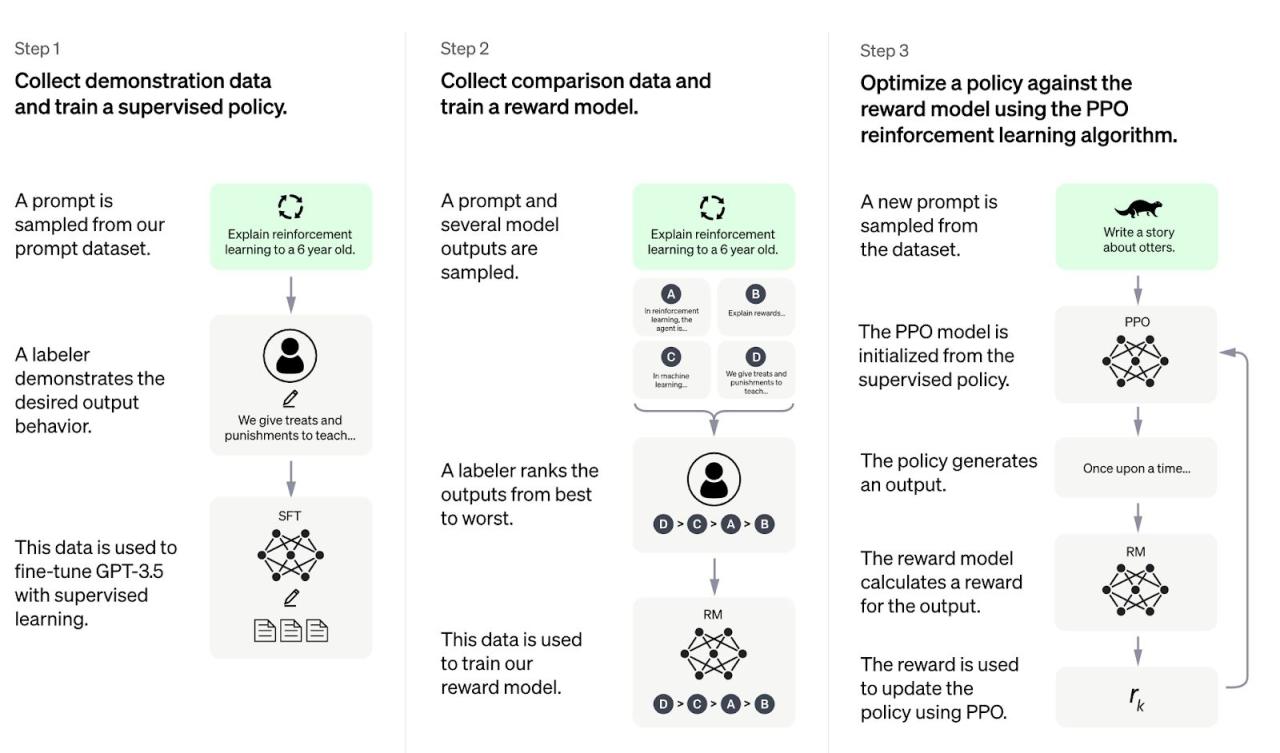
这与 InstructGPT 之间的唯一区别是基本模型:GPT3 与 GPT3.5。GPT3.5 是一个更大的模型,拥有更多的数据。RM -> 奖励模型。
第 1 步:监督微调 (SFT):了解如何回答查询。
第 2 步:使用人工标签训练奖励模型:构建用于对查询进行排名的模型。人们会根据正确性和其他因素对查询进行排名。
第 3 步:使用第 2 步中的 RM 进行强化学习:学习像人一样“说话”。
可以想象,这会使模型变得更驯服,产生的幻觉也会少得多,因为它现在正试图安抚人类主人。
结果
这会产生令人兴奋的结果!根据 OpenAI 的说法,他们的人工标注者“明显更喜欢”InstructGPT 的输出,而不是 GPT 和 GPT(提示),后者指的是 GPT 带有额外提示以遵循说明。
李克特量表/分数只是每个响应的 1-7 评级。